Next Saturday, 8 November 2014, at 19:30 I will be speaking about MySQL Fabric for PyConES 2014 (the Spanish version of the PyCon), the annual meeting point for all developers and enthusiasts of Python in Spain. While I say myself that I am not a developer, a lot of my time as a MySQL consultant requires implementing automatic procedures (backups, health checks, AWS management, …) and for that I mainly use a combination of Python and Bash.
In my talk, which I have titled “MySQL Fabric, a High Availability solution for Connector/Python” I will explain how to setup and configure a set of MySQL servers and Python application clients using Connector/Python in order to provide service resiliency and extra performance for both reads and writes (thanks to its semi-automatic sharding capabilities) on your application. The framework itself (Fabric, part of the MySQL Utilities) is open source and under heavy development (also programmed in Python, of course!). If at any point in your career you suffered from bad database performance or application downtime, you must come to my talk! I will also compare it to other relatively similar solutions, providing its pros and cons. The session will be delivered in English.
Monday next week, on November 3rd, I will be delivering a tutorial on the greatest MySQL European Conference, the Percona Live London 2014. The topic is a natural continuation of the one I delivered last year on the same venue, “Query Optimization with MySQL 5.6: Old and New Tricks“. This year I will be focusing on the newest optimizer changes that we can find not only in the already published 5.6 and MariaDB 10, but also some of the latest features in the still in development MySQL 5.7 and MariaDB 10.1. Topics on this workshop, which I have titled “Query Optimization with MySQL 5.7 and MariaDB 10: Even Newer Tricks“, will include: new 5.7 cost-based optimizer, virtual columns, query rewriter plugin api, new join methods, subquery optimization, sql mode changes, full text search and GIS improvements. All of it with easy-to follow examples and hands-on exercises.
While I will be handling removable media with those same files, and you will be able to follow the explanation fully just by watching my screen, as I will show everything myself, but you will get much more out of the tutorial if you took 5 minutes to prepare your system in advance.
I will be gifting several usb drives among those that take the time to setup their systems beforehand and attend my tutorial as a thank you for helping make the session smoother. Mention me on twitter saying something like “I already have everything prepared for the @dbahire_en tutorial http://dbahire.com/pluk14 #perconalive”, so I can reserve yours!
See you next Monday at 9:00 London time at Orchard 2.
As I mentioned on my last post, where I compared the default configurations options in 5.6 and 5.7, I have been doing some testing for a particular load in several versions of MySQL. What I have been checking is different ways to load a CSV file (the same file I used for testing the compression tools) into MySQL. For those seasoned MySQL DBAs and programmers, you probably know the answer, so you can jump over to my 5.6 versus 5.7 results. However, the first part of this post is dedicated for developers and MySQL beginners that want to know the answer to the title question, in a step-by-step fashion. I must say I also learned something, as I under- and over-estimated some of the effects of certain configuration options for this workload.
Disclaimers: I do not intend to do proper benchmarks, most of the results obtained here were produced in a couple of runs, and many of them with a default configuration. This is intended, as I want to show “bad practices” for people that is just starting to work with MySQL, and what they should avoid doing. It is only the 5.6 to 5.7 comparison that have left me wondering. Additional disclaimer: I do not call myself a programmer, and much less a python programmer, so I apologize in advance for my code- after all, this is about MySQL. The download link for the scripts is at the bottom.
The Rules
I start with a CSV file (remember that it is actually a tab-separated values file) that is 3,700,635,579 bytes in size, has 46,741,126 rows and looks like this:
The import finish time will be defined as the moment the table is crash safe (even if there is some pending IO). That means that for InnoDB, the last COMMIT has to be successful and flush_log_at_trx_commit must be equal to 1, meaning that even if there is pending IO to be made, it is fully durable on disk (it is crash-resistant). For MyISAM, that means that I force a FLUSH TABLES before finishing the test. Those are, of course, not equivalent but it is at least a way to make sure that everything is more or less disk-synced. This is the ending part of all my scripts:
For the hardware and OS, check the specs on this previous post– I used the same environment as the one mentioned there, with the exception of using CentOS7 instead of 6.5.
The naive method
Let’s say I am a developer being tasked with loading a file regularly into MySQL- how would I do that? I would probably be tempted to use a CSV parsing library, the mysql connector and link them together in a loop. That would work, wouldn’t it? The main parts of the code would look like this (load_data_01.py):
# import
insert_node = "INSERT INTO nodes (id, lat, lon, version, timestamp, changeset, uid, user) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)"
with open(CSV_FILE, 'rb') as csv_file:
csv_reader = csv.reader(csv_file, delimiter='\t')
for node in csv_reader:
cursor.execute(insert_node, node)
As I am playing the role of a developer without MySQL experience, I would also use the default configuration. Let’s see what we get (again, that is why I call these “tests”, and not benchmarks). Lower is better:
MySQL Version
5.1.72
5.5.39
5.6.20
5.7.4
Load time (seconds)
4708.594
6274.304
6499.033
6939.722
Wow, is that 5.1 being a 50% faster than the rest of versions? Absolutely not, remember that 5.5 was the first version to introduce InnoDB as the default engine, and InnoDB has additional transactional overhead and usually not good default configuration (unlike MyISAM, which is so simple that the default options can work in many cases). Let’s normalize our results by engine:
MySQL Version
5.1.72
5.5.39
5.6.20
5.7.4
MyISAM
4708.594
5010.655
5149.791
5365.005
InnoDB
6238.503
6274.304
6499.033
6939.722
This seems more reasonable, doesn’t it? However, in this case, it seems that there is a slight regression in single-thread performance as the versions go up, specially on MySQL 5.7. Of course, it is early to draw conclusions, because this method of importing a CSV file, row by row, is one of the slowest ones, and we are using very poor configuration options (the defaults), which vary from version to version and should not be taken into account to draw conclusions.
What we can say is that MyISAM seems to work better by default for this very particular scenario for the reasons I mentioned before, but it still takes 1-2 hours to load such a simple file.
The even more naive method
The next question is not: can we do it better, but, can we do it even slower? A particular text draw my attention when looking at the MySQL connector documentation:
Since by default Connector/Python does not autocommit, it is important to call this method after every transaction that modifies data for tables that use transactional storage engines.
-from the connector/python documentation I though to myself- oh, so maybe we can speedup the import process by committing every single row to the database, one by one, don’t we? After all, we are inserting the table on a single huge transaction. Certainly, a huge number of small transactons will be better! 🙂 This is the slightly modified code (load_data_02.py):
insert_node = "INSERT INTO nodes (id, lat, lon, version, timestamp, changeset, uid, user) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)"
with open('/tmp/nodes.csv', 'rb') as csv_file:
csv_reader = csv.reader(csv_file, delimiter='\t')
for node in csv_reader:
cursor.execute(insert_node, node)
db.commit()
And I do not even have a fancy graphic to show you because after 2 hours, 19 minutes and 39.405 seconds, I canceled the import because only 111533 nodes had been inserted in MySQL 5.1.72 for InnoDB with the default configuration (innodb_flush_log_at_trx_commit = 1). Obviously, millions of fsyincs will not make our load faster, consider this a leason learned.
Going forward: multi-inserts
The next step I wanted to test is how effective grouping queries was in a multi-insert statement. This method is used by mysqldump, and supposedly minimizes the SQL overhead of handling every single query (parsing, permission checking, query planning, etc.). This is the main code (load_data_03.py):
concurrent_insertions = 100
[...]
with open(CSV_FILE, 'rb') as csv_file:
csv_reader = csv.reader(csv_file, delimiter='\t')
i = 0
node_list = []
for node in csv_reader:
i += 1
node_list += node
if (i == concurrent_insertions):
cursor.execute(insert_node, node_list)
i = 0
node_list = []
csv_file.close()
# insert the reminder nodes
if i > 0:
insert_node = "INSERT INTO nodes (id, lat, lon, version, timestamp, changeset, uid, user) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)"
for j in xrange(i - 1):
insert_node += ', (%s, %s, %s, %s, %s, %s, %s, %s)'
cursor.execute(insert_node, node_list)
We tested it with a sample of 100 rows inserted with every query. What are the results? Lower is better:
MySQL Version
5.1.72
5.5.39
5.6.20
5.7.4
MyISAM
1794.693
1822.081
1861.341
1888.283
InnoDB
3645.454
3455.800
2849.299
3032.496
With this method we observe an improvement of the import time of 262-284% from the original time for MyISAM and of 171-229% from the original time for InnoDB. Remember that this method will not scale indefinitely, as we will encounter the package size limit if we try to insert too many rows at the same time. However, it is a clear improvement over the one-row-at-a-time approach.
MyISAM times are essentially the same between versions while InnoDB shows an improvement over time (which may be due to code and optimization changes, but also to the defaults like the transaction log size changing, too), except again between 5.6 and 5.7.
The right method for importing data: Load Data
If you have a minimum of experience with MySQL, you know that there is a specialized keyword for data imports, and that is LOAD DATA. Let’s see how the code would end up looking like by using this option (load_data_04.py):
# data import
load_data = "LOAD DATA INFILE '" + CSV_FILE + "' INTO TABLE nodes"
cursor.execute(load_data)
Simple, isn’t it? With this we are minimizing the SQL overhead, and executing the loop in the compiled C MySQL code. Let’s have a look at the results (lower is better):
MySQL Version
5.1.72
5.5.39
5.6.20
5.7.4
MyISAM
141.414
149.612
155.181
166.836
InnoDB
2091.617
1890.972
920.615
1041.702
In this case, MyISAM has a very dramatic improvement – LOAD DATA speeds up to 12x times the import. InnoDB, again still each one with the default parameters can improve the speed up to 3x times, and more significantly in the newer versions (5.6, 5.7) than the older ones (5.1, 5.5). I predict that this has to do much more with the different configuration of log files than with the code changes.
Trying to improve Load Data for MyISAM
Can we improve the load times for MyISAM? There are 2 things that I tried to do -augmenting the key_cache_size and disabling the Performance Schema for 5.6 and 5.7. I set up the key_cache_size to 600M (trying to fit the primary key on memory) and I set the performance_schema = 0, and I tested the 3 remaining combinations. Lower is better:
MySQL Version
5.1.72
5.5.39
5.6.20
5.7.4
default
141.414
149.612
155.181
166.836
key_buffer_size=600M
136.649
170.622
182.698
191.228
key_buffer_size=600M, P_S = OFF
133.967
170.677
177.724
186.171
P_S = OFF
142.592
145.679
150.684
159.702
There are certain things to notice here:
P_S=ON and P_S=OFF should have no effect for MySQL 5.1 and 5.5, but it brings different results because of measuring errors. We must understand that only 2 significative figures should be taken into account.
key_buffer_cache does not in general improve performance, in fact I would say that it statistically worsens the performance. This is reasonable because after all, I am writing to filesystem cache, and a larger key cache might require costlier memory reservations, or more memory copys. This should be researched further to make a conclusion.
Performance_schema may worsen the performance on this workload, but I am not statistically sure.
MyISAM (or maybe the MySQL server) seems to have slightly worsen its performance for this specific workload (single threaded batch import).
There are more things that I would like to try with MyISAM, like seeing the impact of the several row formats (fixed), but I wanted to follow up for other engines.
Trying to improve Load Data for InnoDB
InnoDB is a much more interesting engine, as it is ACID by default, and more complex. Can we make it as fast as MyISAM for importing?
The first thing I wanted to do is to change the default values of the innodb_log_file_size and innodb_buffer_pool_size. The log is different by default before and after 5.6, and it is not suitable for a heavy write load. I set it for a first test to 2G, as it is the largest size that 5.1 and 5.5 can use (actually, I set it to 2,147,483,136 as it has to be less than 2G), meaning that we have logs of about 4G. I also set the buffer pool for a convenient size, 8GB, enough to hold the whole dataset. Remember that one of the problems why InnoDB is so slow for imports is because it writes the new pages (at least) twice on disk -on the log, and on the tablespace. However, with these parameters, the second write should be mostly buffered on memory. These are the new results (lower is better):
MySQL Version
5.1.72
5.5.39
5.6.20
5.7.4
default
1923.751
1797.220
850.636
1008.349
log_file_size=2G, buffer_pool=8G
1044.923
1012.488
743.818
850.868
Now this is a test that starts to be more reasonable. We can comment that:
Most of the improvements that we had before in 5.6 and 5.7 respect to 5.1 and 5.5 was due to the 10x size in logs.
Still, 5.6 and 5.7 are faster than 5.1 and 5.5 (reasonable, as 5.6 had quite some impresive InnoDB changes, both on code and on configuration)
InnoDB continues being at least 5x slower than MyISAM
Still, 5.7 is slower than 5.6! We are having consistently a 13-18% regression in 5.7 (now I am starting to worry)
I said before that the main overhead of InnoDB is writing the data twice (log and tables). This is actually wrong, as it may actually write it 3 times (on the double write area) and even 4 times, in the binary log. The binary log is not enabled by default, but the double write is, as it protects from corruption. While we never recommend disabling the latter on a production, the truth is that on an import, we do not care if the data ends up corrupted (we can delete it and import it again). There is also some options on certain filesystems to avoid setting it up.
Other features that are in InnoDB for security, not for performance are the InnoDB checksums- they even were the cause of bottlenecks on very fast storage devices like flash PCI cards. In those cases, the CPU was too slow to calculate it! I suspect that that will not be a problem because more modern versions of MySQL (5.6 and 5.7) have the option to change it to the hardware-sped up function CRC32 and, mainly, because I am using a magnetic disk, which is the real bottleneck here. But let’s not believe on what we’ve learned and let’s test it.
The other thing I can check is performance_schema overhead. I’ve found cases of workload where it produces significative overhead, while almost none in others. Let’s also test enabling and disabling it.
These are the results (lower is better):
MySQL Version
5.1.72
5.5.39
5.6.20
5.7.4
default security and monitoring enabled
1044.923
1012.488
743.818
850.868
doublewrite=off
896.423
848.110
483.542
468.943
doublewrite=off,checksums=none
889.827
846.552
488.311
476.916
doublewrite=off,checksums=none,P_S=off
488.273
467.716
There are several things to comment here, some of them I cannot even explain:
The doublewrite feature doesn’t halve the performance, but it impacts it significantly (between a 15-30%)
Without the doublewrite, most of the 5.7 regression goes away (why?)
The doublewrite is also more significative in 5.6 and 5.7 than previous versions of MySQL. I would dare to tell that most of the other bottleneck may have been eliminated (or maybe it is just something like the buffer pool partitions being active by default?)
The innodb checksum makes absolutely no difference for this workload and hardware.
Again, I cannot give statistical significance to the overhead of the performance schema. However, I have obtained very variables results in these tests, having results with a 10% higher latency than the central values of the ones with it disabled, so I am not a hundred percent sure on this.
In summary, with just a bit of tweaking, we can get results on InnoDB that are only 2x slower than MyISAM, instead of 5x or 12x.
Import in MyISAM, convert it to InnoDB
I’ve seem some people at some forums recommending importing a table as MyISAM, then convert it to InnoDB. Let’s see if we can bust or confirm this myth with the following code (load_data_06.py):
load_data = "LOAD DATA INFILE '/tmp/nodes.csv' INTO TABLE nodes"
alter_table = "ALTER TABLE nodes ENGINE=InnoDB"
cursor.execute(load_data)
cursor.execute(alter_table)
These are the comparisons (lower is better):
MySQL Version
5.1.72
5.5.39
5.6.20
5.7.4
LOAD DATA InnoDB
1923.751
1797.220
850.636
1008.349
LOAD DATA MyISAM; ALTER TABLE ENGINE=InnoDB
2075.445
2041.893
1537.775
1600.467
I can see how that could be almost true in 5.1, but it is definitely not true in supported versions of MySQL. It is actually faster than importing twice the table, once for MyISAM and another for InnoDB.
I leave as a homework as a reader to check it for other engines, like MEMORY or CSV [Hint: Maybe we could import to this latest engine in a different way].
Parallel loading
MyISAM writes to tables using a full table lock (although it can perform in some cases concurrent inserts), but InnoDB only requires row-level locks in many cases. Can we speed up the process by doing a parallel loading? This is what I tried to test with my last test. I do not trust my programming skills (or do not have time) to perform the file-seeking and chunking in a performant way, so I will start with a pre-sliced .csv file into 8 chunks. It should not consume much time, but the limited synchronization tools on the default threading library, together with my limited time made me opt for this plan. We only need to understand that we do not start with the exact same scenario in this case. This is the code (load_data_08.py):
NUM_THREADS = 4
def load_data(port, csv_file):
db = mysql.connector.connect(host="localhost", port=port, user="msandbox", passwd="msandbox", database="test")
cursor = db.cursor()
load_data_sql = "LOAD DATA INFILE '" + csv_file + "' INTO TABLE nodes"
cursor.execute(load_data_sql)
db.commit()
thread_list = []
for i in range(1, NUM_THREADS + 1):
t = threading.Thread(target=load_data, args=(port, '/tmp/nodes.csv' + `i`))
thread_list.append(t)
for thread in thread_list:
thread.start()
for thread in thread_list:
thread.join()
And these are the results, with different parameters:
MySQL Version
5.1.72
5.5.39
5.6.20
5.7.4
1 thread, log_file_size=2G, buffer_pool=8G
894.367
859.965
488.273
467.716
8 threads, log_file_size=2G, buffer_pool=8G
752.233
704.444
370.598
290.343
8 threads, log_file_size=5G, buffer_pool=20G
301.693
243.544
4 threads, log_file_size=5G, buffer_pool=20G
295.884
245.569
From this we can see that:
There is little performance changes between loading in parallel with 4 or 8 threads. This is a machine with 4 cores (8 HT)
Parallelization helps, although it doesn’t scale (4-8 threads gives around a 33% speed up)
This is where 5.6 and specially 5.7 shines
A larger transaction log and buffer pool (larger than 4G, only available in 5.6+) still helps with the load
Parallel load with 5.7 is the fastest way in which I can load this file into a table using InnoDB: 243 seconds. It is 1.8x times the fastest way I can load a MyISAM table (5.1, single-threaded): 134 seconds. That is almost 200K rows/s!
Summary and open questions
The fastest way you can import a table into MySQL without using raw files is the LOAD DATA syntax. Use parallelization for InnoDB for better results, and remember to tune basic parameters like your transaction log size and buffer pool. Careful programming and importing can make a >2-hour problem became a 2-minute process. You can disable temporarily some security features for extra performance
There seems to be an important regression in 5.7 for this particular single-threaded insert load for both MyISAM and InnoDB, with up to 15% worse performance than 5.6. I do not know yet why.
On the bright side, there is also an important improvement (up to 20%) in relation to 5.6 with parallel write-load.
Performance schema may have an impact on this particular workload, but I am unable to measure it reliably (it is closer to 0 than my measuring error). That is a good thing.
I would be grateful if you can tell me if I have made any mistakes on my assumptions here.
Of course, this is just a catchy title. As far as I know not all system tables can be converted to InnoDB yet (e.g. grant tables), which makes the header technically false. MyISAM is a very simple engine, and that has some inherent advantages (no transactional overhead, easier to “edit” manually, usually less space footprint on disk), but also some very ugly disadvantages: not crash safe, no foreign keys, only full-table locks, consistency problems, bugs in for large tables,… The 5.7.5 “Milestone 15” release, presented today at the Oracle Open World has an impressive list of changes, which I will need some time to digest, like an in-development (syncronous?) multi-master replication or a revamped query optimizer. But the one very change that I want to highlight today is how the last one of the “big 3” reasons to use MyISAM has finally vanished. For me (and my customers) those reasons were:
Transportable tablespaces
In MyISAM, moving a table in binary format from one server to another was very easy- shutdown the servers and copy the .MYI, .MYD and .frm files. You could even do it in a hot way with the due care: you could copy the table files if you executed the infamous “FLUSH TABLES WITH READ LOCK;” beforehand, and use that as a backup.
Before 5.6, MySQL required a patch for this to work reliably. Now, single tables can be exported and imported without problem in binary format, even between servers.
Fulltext indexes
Fulltext search has never been the strong point of MySQL (and that is why many people combined it with Sphinx or Apache Lucene/Solr). But many users didn’t require a Google Search clone, only a quick way to search on a smallish website, or a description column, and as we know, BTREE indexes wouldn’t help with like '%term%' expressions.
FULLTEXT indexes and searches have been available since MySQL 3.23.23, but only on MyISAM. I do not know about you, but I have found a relatively high number of customers whose reason to continue using MyISAM was only “we need fulltext search”. Starting with MySQL 5.6.4, fulltext support was added to InnoDB, avoiding the need to decide between transactionality and fast string search. While the starts were not precisely great, (specially compared to other more complex, external solutions) and they were released with some important crashing bugs; the latest changes indicate that InnoDB fulltext support is still being worked on in order to increase its performance.
GIS support
This is the one that MySQL engineers added in MySQL 5.7.5. Of course, GIS datatypes were available since MySQL 4.1 for MyISAM, and in 5.0.16 for most other upstream engines, including InnoDB. However, those types are not useful if they cannot be used quickly in common geographical operations like finding if 2 polygons overlap or finding all points that are close to another. Most of those operations require indexing in 2 dimensions, something that doesn’t work very well with standard BTREE indexes. For that, we need R-Trees or Quadtrees, structures that can efficiently index multidimensional values. Up to now, those SPATIAL indexes, as they are called in MySQL syntax, were only available for MyISAM- meaning that you had to decide again between transactions and foreign keys or fast GIS operations. This was one of the reasons why projects like OpenStreetMap migrated to PostGIS, while others used Oracle Spatial Extensions.
To be fair, the list of changes regarding GIS seems quite extensive, and I have been yet unable to have a detailed look at it. But for I can see there is still no support for projections (after all, that would probably require a full overhaul of this feature), and with it, no native distance functions, which makes it not a viable alternative to PostGIS in many scenarios. But I can see how InnoDB support, at least at MyISAM level and beyond that, is a huge step forward. Again, sometimes you do not need a complete set of features for the main MySQL audience, but a set of minimum options to display efficiently something like a map on a website.
MyISAM in a post-myisam world
In summary, these changes, together with the slow but steady migration of system tables to InnoDB format, plus the efforts on reducing transactional overhead for internal temporary tables will allow Oracle to make MyISAM optional in the future.
I will continue to use MyISAM myself in certain cases because sometimes you do not need a fully ACID storage, and it works particularly well for small, read-only datasets -even if you have millions of those (hey, it works well for WordPress.com, so why should you not use it, too?).
Also, it will take years for all people to adopt 5.7, which is not even in GA release yet.
So tell me, are you planning to migrate engine when 5.7 arrives to your production? What are you still using MyISAM for? Which is your favorite 5.7.5 new feature? Which caveats have you found on the new announced features? Send me a message here or on Twitter.
While doing some testing (that I published later here) on the still-in-development MySQL 5.7 I wanted to do some analysis on the configuration to see if the changes in performance were due to the code changes or just to the new MySQL defaults (something that is very common in the migration from 5.5 to 5.6 due to the default transaction log size and other InnoDB parameters). This is a quick post aiming to identify the global variables changed between these two versions.
You could tell me that you could just read the release notes, but my experience (and this is not an exception, as you will see) tells me to check these changes by myself.
I do not include changes in the performance_schema tables, as I was running these particular tests with performance_schema = OFF. I also do not include “administrative changes”, my name for variables that do not influence the behaviour or performance of mysql, like server_uuid which will be unique for different instances and version and innodb_version, which obviously have been changed from 5.6.20 to 5.7.4-m14. Please note that some changes have also been back-ported to 5.6, so not being shown here, or were already available in previous releases of 5.7.
Regarding potential incompatibilities, all deprecated variables but one were literally useless, and I did not find them setup usually except for innodb_additional_mem_pool_size, which was, in my experience, always configured by mistake, as it had absolutely no effect in recent versions of InnoDB. The exception is binlogging_impossible_mode, which had been added in 5.6.20 and probably not merged in time for this 5.7 milestone. It will probably be added in the future with equivalent functionality. An interesting feature, I would add.
max_statement_timeout and have_statement_timeout comes from the merge or reimplementation of the Twitter Statement Timeout functionality. Nice change to see upstream.
default_authentication_plugin is not a new feature, it just has been moved from a server parameter to a full global variable that can be inspected (but not changed) at runtime. The real change here is default_password_lifetime, which was really missing on the 5.6 release- automatic password expiration (without having to do manually PASSWORD EXPIRE). What I find amusing is the default value: 360 (passwords expire approximately once a year). I am not saying that that is a right or wrong default, but I predict a lot of controversy/confusion over that. There is more to talk about about authentication changes, but I will not expand it here, as it does not concern configuration variables.
Some interesting additions to InnoDB, too, like the innodb_page_cleaners variable, allowing multiple threads for flushing pages from the buffer pool in parallel, and which was the subject of a recent discussion about a certain benchmark. Also we have additions like some extra flexibility regarding the transaction log caching configuration and the location of temporary tables in InnoDB format, but I consider those lesser changes to go over them in detail.
log_warnings has changed and it has not been documented. But to be honest, its functionality is being deprecated for log_error_verbosity, a newly introduced variable that makes by default all errors, warnings and notes to be logged by default. I have submitted bug #73745 (now fixed) about this.
A new variable, rbr_exec_mode, seems to have been added in 5.7.1, but it is not documented anywhere in the server variables section or on the release notes, only on that developer’s blog. It allows setting at session level an IDEMPOTENT mode when replicating events in row format, ignoring all conflicts found. I’ve created a bug #73744 for this issue (now fixed).
There has been several performance_schema changes; I will not go over each of them here. Please note that performance_schema_max_statement_classes is not a real change, as that is calculated at startup time, it does not have a fixed value.
Session tracking variables were added for notification of session changes when using the C connector
In summary, some interesting changes, only one default change that may alter the performance (eq_range_index_dive_limit), and nothing that will create problems for a migration, with only two own-predicted exceptions:
Instances of the (useless for a long time, as mentioned above) variable innodb_additional_mem_pool_size failing with:
, which just should be deleted from the configuration file.
And the expiration time set by default to 1 year, that may create lots of:
ERROR 1862 (HY000): Your password has expired.
or even create some difficult-to-debug problems in older drivers, as we had experienced with this functionality in 5.6. I would like in particular your opinion about software defaults for password expiration, as I do not consider myself a security expert. As usual, you can comment here or on Twitter.
EDIT: Morgan Tocker, from Oracle, has commented via twitter that “innodb_additional_mem_pool_size had been useless for a long time (since the plugin), and that the reason for the change now is the additional problems of parsing but ignoring options“. I am not complaining about those changes, I actually think that they should have been done long time ago to prevent those very errors, I am just putting here a solution for what I think can be frequent mistakes on migration. Incompatibility is sometimes the way to go.
On my post last week, I analysed some of the most common compression tools and formats, and its compression speed and ratio. While that could give us a good idea of the performance of those tools, the analysis would be incomplete without researching the decompression. This is particularly true for database backups as, for those cases where the compression process is performed outside of the production boxes, you may not care too much about compression times. In that case, even if it is relatively slow, it will not affect the performance of your MySQL server (or whatever you are using). The decompression time, however, can be critical, as it may influence in many cases the MTTR of your whole system.
Testing environment
I used the same OpenStreetMap node MySQL dump in CSV format that I mentioned on my previous post, and -as some tools used the same format (and they should be compatible), but resulted on different compressed ratio- I chose the smallest resulting file for each of them. Here it is a table with the compressed size per format, as a reminder:
format
size (bytes)
original .csv (no compression)
3700635579
gzip
585756379
bzip2
508276130
bzip2 (pbzip2-compressed)
508782016
7z
354107250
lzip
354095395
lzo
782234410
lz4
816582329
Please note that while p7zip and lzip/plzip used the same algorithm, the file format is different. Also please notice the usage of two different compressed files for bzip2: the reason for that will be clarified later.
The hardware specs were the same as for the last post: an almost-idle Intel Quad Core i7-3770@3.40GHz with hyper threading, exposing 8 cpus to the kernel. 32 GB of ram. 2 spinning disks of 3 TB in RAID 1. The filesystem type was ext4 with the default OS options. The operating system had changed to CentOS 7, however.
The methodology was similar as before, for each tool, the following command was executed several times:
$ time [tool] -d -c < nodes.csv.[format] > nodes.csv
Except for dd and 7za, where the syntax is slightly different.
The final file was stored on a different partition of the same RAID. The final file was checked for correction (the uncompressed file was exactly the same as the original one) and deleted after every execution. I will not repeat here my disclaimer about the filesystem cache usage, but I also added the dd results as a reference.
Global results
This is my table of final results and the analysis and discussion follows bellow:
These data can be seen more easily, as usual, on a bidimensional graph. Here the X axis represents the median speed of decompression in MB/s (more is better) and the Y axis represents the compressed ratio in percentage of the compressed size over the original size (less is better):
(not plotted: dd, as it would appear with a 100% compression ratio).
CPU usage was polled every second, and so it was the memory usage, that in no test for any of the tools was over 1MB.
In this case I have plotted the function y = x*0.01+12 over the points and, while there is a clear tendency of better compression ratios requiring more time to decompress, the correlation is weaker than on the compression case.
The last thing I want to remark about the global results is that I have not tried variations in parameters for decompression, as in most cases there are little to no options for this process, and the algorithms will do essentially the same for a file that was created with --fast than another created with --best.
Decompressing gzip and bzip2 formats
Unsurprisingly, the gzip file took less time to decompress than bzip with the generic GNU tools (56 seconds vs. 17). I used GNU gzip 1.5 and bzip2 1.0.6. I said everything I had to say about the advantages and disadvantages of using the most standard tools, so I will not repeat myself, but I wanted to reiterate the idea that gzip is a great tool for fast compression processes when there is not an alternative, as it got a mean throughput of almost 203 MB/s when decompressing our test file.
Of course, the next step was testing decompressing in parallel, and for that I had pigz 2.3.1 and pbzip2 v1.1.6. As a side note, I would like to mention that, at the time of this writing, there were no rpm packages for pbzip2 for CentOS 7 in the base distribution nor on EPEL (which is currently in beta for version 7). I used the package for RHEL6.
However, when looking at the pigz results we can realise that, while there is certainly an improvement on speed (just over 7 seconds), it is not as dramatic as the 4x+ improvement that we had on compression. Also, if we look at the cpu usage, we can realise that the maximum %CPU usage is never over 170. I found the reason for that while looking at the documentation: while pigz uses several threads for read and write I/O, it is unable to parallelise the core gzip decompression algorithm. The improvement over standard gzip -however- is there, with almost 500 MB/s of decompression bandwidth.
When checking pbzip2, on my first try, I realised that there was no parallelization at all, and that the timing results were essentially the same as with regular bzip2. I searched for answers on the documentation and I found that and the reason for that was that decompression in parallel was possible (unlike gzip), but only for files created by pbzip2 itself. In other words, both bzip2 and pbzip2 create files with a compatible format (they can be decompressed with each other), but parallelization is only fully possible if they are created and decompressed with pbzip2. To test that second case, I got the best-compressed file that I got from my previous results (which was slightly larger than the one created with bzip2) and retried the tests. That is why there are two different rows on the global results for pbzip2.
In that second scenario, pbzip2 was a real improvement over bzip2, obtaining decompression rates of 356 MB/s, roughly equivalent to the results of a raw filesystem copy.
As it was expected, multiple threads of decompression is a clear advantage on SMP systems, with the usual disclaimers of extra resources consumed and the fact that, as just seen, it is not possible for all file formats.
Lzma decompression
The next group to test is lzma-based tools: Lzip 1.7, p7zip 9.20 and plzip 1.2-rc2. Again, lzip was not available on EPEL-7, and the RedHat6 version was used, and plzip was compiled from source, as we had to do previously.
Lzma algorithm was classified as a slow but good-compression algorithm on our previous results. A similar thing can be extrapolated for decompression: both lzip and 7za provide decompression times of around 30 seconds, with throughputs near the 100 MB/s. Although p7zip seems to be a bit better paralleled than lzip (with %cpu usage reaching 150), both provide essentially a mono-thread decompression algorithm. Plzip provides a better parallelization, reaching a maximum %cpu of 290, but the throughput never reaches the 200 MB/s.
The general evaluation is that they are clearly better tools than single-threaded gzip and bzip2, as they provide similar decompression bandwidths but with much better compression ratios.
Fast tools: lzop and lz4
Finally, we have left the fast compression and decompression tools, in our tests lzop v1.03 and lz4 r121. In this case we can testify the the claims that lz4, while providing similar compression speed than lzop, it is faster for decompression: almost doubling the rate (580 MB/s for lzop vs. 1111 MB/s for lz4). Obviously, the only reason those results are possible is because the filesystem cache is kicking in, so take this results with the due precaution. But it shows what kind of decompression bandwidth can be achieved when the disk latency is not the bottleneck.
When the time of the test is so small, I would recommend repeating it with larger filesizes and/or limiting the effect of the filesystem cache. I will leave that as a homework for the reader.
Conclusion
Aside from the found limitations of several of the tools regarding decompression parallelization (pigz, pbzip2), no highly surprising results have been found. Fast compression tools are fast to decompress (I have become a fan of lz4) and best-compression tools are slower (plzip seems to work very well if we are not constrained by time and CPU). As usual, I will leave you with my recommendation of always testing on your environment, with your own files and machines.
Which compression tool(s) do you use for MySQL (or any other database backups)? Leave me a comment here or on Twitter.
This week we are talking about size, which is a subject that should matter to any system administrator in charge of the backup system of any project, and in particular database backups.
I sometimes get questions about what should be the best compression tool to apply during a particular backup system: gzip? bzip2? any other?
The testing environment
In order to test several formats and tools, I created a .csv file (comma-separated values) that was 3,700,635,579 bytes in size by transforming a recent dump of all the OpenStreetMap nodes of the European portion of Spain. It had a total of 46,741,126 rows and looked like this:
In fact, the original file is really a tsv (tab-separated values), not a csv, but only because I am lazy when importing/exporting to MySQL to add the extra FIELDS SEPARATED BY ','. You can download this file in 7z format, or create your own from the Geofabrik OpenStreetMap Data Extracts.
All tests were done on an almost-idle Intel Quad Core i7-3770@3.40GHz with hyper threading, exposing 8 cpus to the kernel. 32 GB of ram. 2 spinning disks of 3 TB in RAID 1. All running on CentOS 6.5 x86_64. The filesystem type was ext4 with the default OS options.
On-table sizes
For an import to MySQL, I proposed the following table structure:
And these are the sizes on database (once we made sure there were no pending write operations):
MySQL MyISAM data file (.MYD): 2,755,256,596 bytes.(*)
MySQL InnoDB tablespace (.ibd): 3,686,793,216 bytes.
MySQL InnoDB tablespace using row_format=compressed (.ibd): 1,736,441,856 bytes.
Why is it taking more space on plain text than on the database? Well, despite databases being optimised for fast access and not for space, as we are using very compact set of datatypes (integers and timestamps instead of strings), actually saving disk space. This is why a proper database design is critical for performance!
We can see that one of the few reason why people are still using MyISAM is because it is a very simple and compact format. (*)However, to be fair, we are not having into account the extra 674,940,928 bytes for the primary key (.MYI), making the difference not so big. On the other side, we are not taking into account that InnoDB index size goes up quite significantly when using multiple secondary keys (due to the storage of the primary key, if it is large enough) and the many other structures (tablespace 0, transaction logs) that are needed for InnoDB to work properly, shared with other tables. In general, it is impossible to do a fair comparison between MyISAM and InnoDB because we are comparing apples and oranges.
What it is clear is that compression (in this case I used the default InnoDB zlib algorithm with the default level of compression-6) helps reduce on-disk size, potentially helping for some specific scenarios: more tables to fit in SSDs, or less IOPS for a disk-bound database. On the other side, the initial load from a file took significantly more. I do not want to show time measurements for the different table imports because it is not trivial to account the actual time to disk due to all the buffering occurring at database level, and giving the time of SQL execution would be unfair. I talk more about import times in this post.
Global results
The sizes in table are only showed as reference, our main goal was to test the several tools available for compressing the original nodes.csv file. I constrained myself to some of the most popular ones, and you can see the final results on the following table (analysis, explanation and discussion or results follows afterwards):
As you can see, I evaluated several tools on their default modes, plus additionally “high-compression mode” and a “fast mode”. For them, I tried to evaluate 3 different parameters important for the creation of compressed files: time to completion, final file size and resources used. Please note that I only evaluated compression tools, and not archiving ones (like tar or zip). The latter tools can usually use different algorithms for compressing each file individually or the final full archive.
The first data column shows the number of seconds of wall clock time that took for the process to write the compressed file to a different partition on the same set of RAID disks. Several runs of:
time [application] -c < nodes.csv > /output/nodes.csv.[format]
were executed (except for 7z and dd, where the syntax is different) and the median vale was taken, in order to minimise measure errors due to external factors. For each run, the final file was checked for correctness (the compressed file is deterministic and it can be extracted into the original file without errors or differences) and then deleted. The results are not too scientific, as the filesystem cache can be heavily used for both reads and writes, but I tried to focus on that scenario in particular. An execution of dd (copying the file without compression) is also shown as a control value.
I think the second and third data columns are self-explanatory: the file size, in bytes, of the compressed file and how it compares with the original file.
The last column tries to measure the max and min CPU usage, as reported by the operating system during compression. However, due to the cpu scheduler, and the fact that most tools have a synchronisation period at the beginning and at end of the execution, together with the fact that is was obtained by polling its value at intervals, it is not very significative except for checking the parallelism of the algorithm used. Values greater than 100 means that more than core/thread is being used for compression.
I did not registered the memory usage (the other important resource) because even on ultra modes, its usage was not significative for my 32 GB machine (less than 1/2 GB every time, most of the times much less). I considered it was something one should not worry too much for a machine that should have enough free RAM like a database server. What you probably would like to have into account is the effects on the filesystem cache, as that could impact directly on the MySQL performance. Preventing backup page reads and writes going into the filesystem cache can be done playing around with the flag POSIX_FADV_DONTNEED. I want to mention also that there are tools, like bzip, that have a small footprint mode: bzip2 --small.
The global results may be appreciated much more clearly plotted on a bidimensional graph. I have plotted the obtained values with the time to compression on the X axis (lower is better) and the compression ratio on the Y axis (lower is better):
Not plotted: dd (100% compression ratio), 7za “ultra” (>21 minutes for compression) and lzip (>35 minutes for compression).
In general, we can see that there are no magical tools, and that a better compression ratio requires more time (size is inversely proportional to time). I have plotted also the function y = 200/x + 9. That, or something like y = 200/x+9.5(it is difficult to provide a good correlation with so little number of matches, most of them unrelated) seems to provide the lower limit of ratio per unit of time, suggesting that 9%-9.5% would be the maximum compress ration obtainable for that file with the available tools at the moment.
Let’s analyse what are the weaknesses and strong points of every compression format.
The well-known gzip and bzip2
If you want compatibility, gzip and bzip2 are the kings. Not only they are widely recognised compression formats, but the tools for compress and decompress are preinstalled in most unix-like operating systems. Probably Windows is the only operating system that doesn’t support gzip by default. gzip and bzip2 are the only compressions with its own letter on tar (with compress on BSD and xz on GNU).
Compatibility and availability are the strong points of these tools, however, if we look at the graph, we can see that they are relatively far from the line I mentioned as “ideal” in time/size ratio. bzip2 provides a better compression ratio than gzip in exchange of more cpu cycles, but both tools are single-threaded and they do not shine in any aspect. Surprisingly enough, bzip2 -1 provided me with a worse compression time and better rate than standard bzip2 execution, and the manual for the gnu version provides an explanation for that:
The --fast and --best aliases are primarily for GNU gzip
compatibility. In particular, --fast doesn't make things significantly faster. And --best
merely selects the default behaviour.
Probably the best use I would recommend for this tools is gzip --fast (equivalent to gzip -1) that, while not providing a great compression rate, it does it in a very fast way even for a single-thread application. So it can be useful in those cases where we want to maximise speed without taking many resources. In other cases, where tool availability is not a problem, I would recommend you trying other tools with either better speed or better compression ratio.
I used GNU versions gzip 1.3.12 and bzip2 1.0.6.
Parallel compression tools: pigz and pbzip2
Things get more interesting if you use the parallel versions of gzip and bzip2 on a multi-core system. While there are more than one version, I choose pigz 2.3.1 and pbzip2 1.1.6 for my tests. While they are not part of the official Red Hat/CentOS repositories, they can found on EPEL and Debian repositories.
Both tools auto-detect the number of cores I had and performed the compression in 8 threads, providing comparable compression ratios in about 4 times less time. The obvious downsize is that in a high-demanding environment, like a MySQL server under considerable load, you may not want/can’t provide full CPU resources to the backup process. But if you are doing the compression on a separated dedicated server, parallelization is something you should get advantage of, as in general CPU will be the main bottleneck on a compression algorithm.
Again, as a highlight, pigz with the default parameters provided me a good compression ration (16,89%) in less than 28 seconds- that is compressing at close to 130MB/s for my modest hardware (that is more than a third of my copy rate, 350MB/s).
As a side note, while pbzip2 accepts a compression level as a parameter, the default compression level is -9.
lzma implementations: lzip, 7zip and plzip
The next tests performed were simply different lzma implementations, an algorithm that has the fame of providing very good compression rates.
I started with lzip. It is not on the official repositories, so I got it from EPEL, installing lzip 1.7. The compression ratio was, effectively, the best of all other algorithms (close to 9.5%) but it took 35 minutes and 38 seconds to produce the output. Not only the algorithm was to blame: it used a single thread, hence the delay.
After that, I tried p7zip 9.20, in particular the unix tool 7za. This one the only tool tested that did not conformed to the gzip parameters. I had to execute it using:
time 7za a /output/nodes.csv.7z nodes.csv
Please note that p7zip is an archiver tool, but I made an exception in order to test an alternative implementation of lzma.
The results were better: while the tool provided a slightly worse compression ration (10.29%), thanks to some kind of execution in more than one thread, the execution time was reduced to just under 14 minutes. I also tested a suggested “ultra” mode found in the 7za manual, with the following parameters:
-t7z -m0=lzma -mx=9 -mfb=64 -md=32m -ms=on
In short: maximising the memory usage, compression level and dictionary size -aside from enforcing the archive format and compression algorithm. While this provided with a smaller file size (but only 25 MB smaller, less than a 1% of the original file), the time went up to more than 21 minutes.
I wanted to try a real parallel implementation of lzma, and plzip was exactly that. I could not find a rpm package anywhere, so I downloaded and installed from source code Lzlib 1.5 and plzip 1.2-rc2. The results were really good, as expected. plzip provided comparable results to “pigz -9” when running in “fast mode”; but by default, in only 3m37s I got a 359MB compressed file, or 10.17% of the original file. I then tried to emulate the ultra settings of p7zip (with -9 -m 64 -s 33554432) and got the winner tool in compression ratio (9.57%) in only 7 minutes and 6.486 seconds.
Obviously, the same restrictions that I mentioned for the other parallel tools apply here: usage of multiple cpus may be discuraged for a very busy server, but if you are storing the backups for long-term on a separate server, you may want to have a look at this possibility. In any case, most parallel tools have a way to limit the number of threads created (for example with the --threads option in lzip).
Fast compression tools: lzop and lz4
I didn’t want to finish my testing without having a look some of the high-bandwidth compression tools, and I choose 2: lzop and lz4. While I had to install lz4 r119 from EPEL, lzop v1.02rc1 is part of the base packages of Red Hat/CentOS.
They both provide what they promise: very fast compression algorithms (in some cases, faster than a plain copy of a file, as they are not CPU-bound but they have to write less amount of data) in exchange for worse compression ratios (21-30%). For the example file, on my machine, I got better performance for lz4 than lzop, offering similar ratios but in less time (8.5 vs. 15.5 seconds). So if I had to choose, I would probably would use lz4 over lzop in my particular case. Additionally, although it has not been tested, lz4 boasts of having better decompression speeds.
As a negative highlight, I would recommend against using lzop -9, as there are tools that could get you better compression ratios in half the time. lz4 did not perform well also with a higher compression level, so I recommend you to stick to the defaults or lower compression levels for these tools (in fact, lz4 defaults to -1).
Conclusion
I didn’t test other tools like compress (Lempel-Ziv), xz (lzma2) or QuickLZ, but I do not expect too many deviations from the patterns we have seen: time needed is inversely proportional to compression level. If you want fast compression times, go for lz4. If you want a small file size, go for an implementation of lzma, like p7zip. bzip and gzip formats are good options when compatibility is important (e.g. releasing a file), but when possible, use a parallel compress implementation to improve its performance (plzip, pbzip2, pigz). We can even use a combination of tools for our backups, for example, export our tables in binary format using lz4 to get them outside of the mysql server, and later, on a separate server, convert it to lzma for long-term storage.
I would also tell you to try the compression methods for your particular dataset and hardware, as you may get different compression ratios and timings, specially depending on the amount of memory available for filesystem caching, your cpu(s) and your read and write rate from secondary storage. What I have tried to do with this, however, is a starting point for you to get your own conclusions.
Do you agree with me? Do you think I am wrong at some point? Did you miss something? Write a comment or send me a replay on twitter or by email.
There are very interesting changes for database administrators in these new releases, among which I would like to highlight the fact that installer now chooses XFS as its filesystem by default, which substitutes ext4 as the preferred format for local data storage. Red Hat EL7 also includes Btrfs as a tech preview.
Regarding packages, the most impacting change is arguable the update of both MySQL and PostgreSQL versions, indeed in a need of an update, as the previous version of Red Hat, 6.5, still featured 5-year old versions of both RDBMSs, and both are currently in end of life support. The biggest surprise is that Red Hat has opted to choose MariaDB 5.5, and not Oracle, as the default MySQL-like vendor. This has the hilarious consequence that Oracle Linux actually distributes its competitor version, MariaDB on its repositories, with the aim of being 100% compatible. The difference is that, of course, Oracle offers its latest MySQL version in yum repositories, and as a consequence, it is available for install on all Red Hat-compatible versions.
Pre-requisites
In this tutorial we will show how to install MySQL 5.6 on CentOS 7, useful for those that prefer to deploy the latest MySQL GA release. 5.6 introduces a lot of improvements over MySQL 5.5, and given that Red Hat EL7 has a support cycle of at least ten years, it may become very outdated in the future. The process we are about to show for CentOS 7 will be identical on RHEL 7 and, to some extent, other yum-based distributions like the latest versions of Fedora and Amazon Linux.
Please note that the following tutorial supposes that no previous version of MySQL or MariaDB is already installed. You can use the following command: rpm -qa | grep -i mysql to check for MySQL packages that may be previously installed and you can delete them with the yum remove command.
Tutorial
The first step is to setup Oracle’s MySQL repository, for that, we can go to the mysql.com website, click on “Downloads“, then “Yum repository” and then “Red Hat Enterprise Linux 7”. At the moment of the writing of these lines, this version of the repository setup package is still in beta, but I had no problems to install it with several combinations of software and hardware. Select “Download” and you can choose to login or create an Oracle account. We can also skip that step and just copy the link on “No thanks , just start my download”. This will provide us the address of the rpm to auto-configure the MySQL Community Server repository.
Now, if we execute on the terminal:
$ sudo yum install http://dev.mysql.com/get/mysql-community-release-el7-5.noarch.rpm
[sudo] password for training:
Loaded plugins: fastestmirror
mysql-community-release-el7-5.noarch.rpm | 6.0 kB 00:00:00
Examining /var/tmp/yum-root-uI5SBL/mysql-community-release-el7-5.noarch.rpm: mysql-community-release-el7-5.noarch
Marking /var/tmp/yum-root-uI5SBL/mysql-community-release-el7-5.noarch.rpm to be installed
Resolving Dependencies
--> Running transaction check
---> Package mysql-community-release.noarch 0:el7-5 will be installed
--> Finished Dependency Resolution
Dependencies Resolved
==============================================================================================================================
Package Arch Version Repository Size
==============================================================================================================================
Installing:
mysql-community-release noarch el7-5 /mysql-community-release-el7-5.noarch 4.3 k
Transaction Summary
==============================================================================================================================
Install 1 Package
Total size: 4.3 k
Installed size: 4.3 k
Is this ok [y/d/N]: y
Downloading packages:
Running transaction check
Running transaction test
Transaction test succeeded
Running transaction
Installing : mysql-community-release-el7-5.noarch 1/1
Verifying : mysql-community-release-el7-5.noarch 1/1
Installed:
mysql-community-release.noarch 0:el7-5
Complete!
We can check that the repository is effectively active by running:
$ sudo yum repolist enabled | grep "mysql.*-community.*"
[sudo] password for training:
mysql-connectors-community/x86_64 MySQL Connectors Community 9
mysql-tools-community/x86_64 MySQL Tools Community 4
mysql56-community/x86_64 MySQL 5.6 Community Server 49
We have done a one-time configuration that will allow us to easily install and keep to date our MySQL installation.
The next step is actually installing the server packages. For that, we write:
$ sudo yum install mysql-community-server
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* base: centos.mirror.xtratelecom.es
* extras: centos.mirror.xtratelecom.es
* updates: centos.mirror.xtratelecom.es
Resolving Dependencies
--> Running transaction check
---> Package mysql-community-server.x86_64 0:5.6.19-2.el7 will be installed
--> Processing Dependency: mysql-community-common(x86-64) = 5.6.19-2.el7 for package: mysql-community-server-5.6.19-2.el7.x86_64
--> Processing Dependency: mysql-community-client(x86-64) = 5.6.19-2.el7 for package: mysql-community-server-5.6.19-2.el7.x86_64
--> Processing Dependency: perl(warnings) for package: mysql-community-server-5.6.19-2.el7.x86_64
--> Processing Dependency: perl(strict) for package: mysql-community-server-5.6.19-2.el7.x86_64
--> Processing Dependency: perl(if) for package: mysql-community-server-5.6.19-2.el7.x86_64
--> Processing Dependency: perl(Sys::Hostname) for package: mysql-community-server-5.6.19-2.el7.x86_64
--> Processing Dependency: perl(POSIX) for package: mysql-community-server-5.6.19-2.el7.x86_64
--> Processing Dependency: perl(Getopt::Long) for package: mysql-community-server-5.6.19-2.el7.x86_64
--> Processing Dependency: perl(File::Temp) for package: mysql-community-server-5.6.19-2.el7.x86_64
--> Processing Dependency: perl(File::Spec) for package: mysql-community-server-5.6.19-2.el7.x86_64
--> Processing Dependency: perl(File::Path) for package: mysql-community-server-5.6.19-2.el7.x86_64
--> Processing Dependency: perl(File::Copy) for package: mysql-community-server-5.6.19-2.el7.x86_64
--> Processing Dependency: perl(File::Basename) for package: mysql-community-server-5.6.19-2.el7.x86_64
--> Processing Dependency: perl(Fcntl) for package: mysql-community-server-5.6.19-2.el7.x86_64
--> Processing Dependency: perl(Data::Dumper) for package: mysql-community-server-5.6.19-2.el7.x86_64
--> Processing Dependency: perl(DBI) for package: mysql-community-server-5.6.19-2.el7.x86_64
--> Processing Dependency: net-tools for package: mysql-community-server-5.6.19-2.el7.x86_64
--> Processing Dependency: libaio.so.1(LIBAIO_0.4)(64bit) for package: mysql-community-server-5.6.19-2.el7.x86_64
--> Processing Dependency: libaio.so.1(LIBAIO_0.1)(64bit) for package: mysql-community-server-5.6.19-2.el7.x86_64
--> Processing Dependency: /usr/bin/perl for package: mysql-community-server-5.6.19-2.el7.x86_64
--> Processing Dependency: libaio.so.1()(64bit) for package: mysql-community-server-5.6.19-2.el7.x86_64
--> Running transaction check
---> Package libaio.x86_64 0:0.3.109-12.el7 will be installed
---> Package mysql-community-client.x86_64 0:5.6.19-2.el7 will be installed
--> Processing Dependency: mysql-community-libs(x86-64) = 5.6.19-2.el7 for package: mysql-community-client-5.6.19-2.el7.x86_64
--> Processing Dependency: perl(Exporter) for package: mysql-community-client-5.6.19-2.el7.x86_64
---> Package mysql-community-common.x86_64 0:5.6.19-2.el7 will be installed
---> Package net-tools.x86_64 0:2.0-0.17.20131004git.el7 will be installed
---> Package perl.x86_64 4:5.16.3-283.el7 will be installed
--> Processing Dependency: perl-libs = 4:5.16.3-283.el7 for package: 4:perl-5.16.3-283.el7.x86_64
--> Processing Dependency: perl(Socket) >= 1.3 for package: 4:perl-5.16.3-283.el7.x86_64
--> Processing Dependency: perl(Scalar::Util) >= 1.10 for package: 4:perl-5.16.3-283.el7.x86_64
--> Processing Dependency: perl-macros for package: 4:perl-5.16.3-283.el7.x86_64
--> Processing Dependency: perl-libs for package: 4:perl-5.16.3-283.el7.x86_64
--> Processing Dependency: perl(threads::shared) for package: 4:perl-5.16.3-283.el7.x86_64
--> Processing Dependency: perl(threads) for package: 4:perl-5.16.3-283.el7.x86_64
--> Processing Dependency: perl(constant) for package: 4:perl-5.16.3-283.el7.x86_64
--> Processing Dependency: perl(Time::Local) for package: 4:perl-5.16.3-283.el7.x86_64
--> Processing Dependency: perl(Storable) for package: 4:perl-5.16.3-283.el7.x86_64
--> Processing Dependency: perl(Socket) for package: 4:perl-5.16.3-283.el7.x86_64
--> Processing Dependency: perl(Scalar::Util) for package: 4:perl-5.16.3-283.el7.x86_64
--> Processing Dependency: perl(Pod::Simple::XHTML) for package: 4:perl-5.16.3-283.el7.x86_64
--> Processing Dependency: perl(Pod::Simple::Search) for package: 4:perl-5.16.3-283.el7.x86_64
--> Processing Dependency: perl(Filter::Util::Call) for package: 4:perl-5.16.3-283.el7.x86_64
--> Processing Dependency: perl(Carp) for package: 4:perl-5.16.3-283.el7.x86_64
--> Processing Dependency: libperl.so()(64bit) for package: 4:perl-5.16.3-283.el7.x86_64
---> Package perl-DBI.x86_64 0:1.627-4.el7 will be installed
--> Processing Dependency: perl(RPC::PlServer) >= 0.2001 for package: perl-DBI-1.627-4.el7.x86_64
--> Processing Dependency: perl(RPC::PlClient) >= 0.2000 for package: perl-DBI-1.627-4.el7.x86_64
---> Package perl-Data-Dumper.x86_64 0:2.145-3.el7 will be installed
---> Package perl-File-Path.noarch 0:2.09-2.el7 will be installed
---> Package perl-File-Temp.noarch 0:0.23.01-3.el7 will be installed
---> Package perl-Getopt-Long.noarch 0:2.40-2.el7 will be installed
--> Processing Dependency: perl(Pod::Usage) >= 1.14 for package: perl-Getopt-Long-2.40-2.el7.noarch
--> Processing Dependency: perl(Text::ParseWords) for package: perl-Getopt-Long-2.40-2.el7.noarch
---> Package perl-PathTools.x86_64 0:3.40-5.el7 will be installed
--> Running transaction check
---> Package mariadb-libs.x86_64 1:5.5.37-1.el7_0 will be obsoleted
---> Package mysql-community-libs.x86_64 0:5.6.19-2.el7 will be obsoleting
---> Package perl-Carp.noarch 0:1.26-244.el7 will be installed
---> Package perl-Exporter.noarch 0:5.68-3.el7 will be installed
---> Package perl-Filter.x86_64 0:1.49-3.el7 will be installed
---> Package perl-PlRPC.noarch 0:0.2020-14.el7 will be installed
--> Processing Dependency: perl(Net::Daemon) >= 0.13 for package: perl-PlRPC-0.2020-14.el7.noarch
--> Processing Dependency: perl(Net::Daemon::Test) for package: perl-PlRPC-0.2020-14.el7.noarch
--> Processing Dependency: perl(Net::Daemon::Log) for package: perl-PlRPC-0.2020-14.el7.noarch
--> Processing Dependency: perl(Compress::Zlib) for package: perl-PlRPC-0.2020-14.el7.noarch
---> Package perl-Pod-Simple.noarch 1:3.28-4.el7 will be installed
--> Processing Dependency: perl(Pod::Escapes) >= 1.04 for package: 1:perl-Pod-Simple-3.28-4.el7.noarch
--> Processing Dependency: perl(Encode) for package: 1:perl-Pod-Simple-3.28-4.el7.noarch
---> Package perl-Pod-Usage.noarch 0:1.63-3.el7 will be installed
--> Processing Dependency: perl(Pod::Text) >= 3.15 for package: perl-Pod-Usage-1.63-3.el7.noarch
--> Processing Dependency: perl-Pod-Perldoc for package: perl-Pod-Usage-1.63-3.el7.noarch
---> Package perl-Scalar-List-Utils.x86_64 0:1.27-248.el7 will be installed
---> Package perl-Socket.x86_64 0:2.010-3.el7 will be installed
---> Package perl-Storable.x86_64 0:2.45-3.el7 will be installed
---> Package perl-Text-ParseWords.noarch 0:3.29-4.el7 will be installed
---> Package perl-Time-Local.noarch 0:1.2300-2.el7 will be installed
---> Package perl-constant.noarch 0:1.27-2.el7 will be installed
---> Package perl-libs.x86_64 4:5.16.3-283.el7 will be installed
---> Package perl-macros.x86_64 4:5.16.3-283.el7 will be installed
---> Package perl-threads.x86_64 0:1.87-4.el7 will be installed
---> Package perl-threads-shared.x86_64 0:1.43-6.el7 will be installed
--> Running transaction check
---> Package perl-Encode.x86_64 0:2.51-7.el7 will be installed
---> Package perl-IO-Compress.noarch 0:2.061-2.el7 will be installed
--> Processing Dependency: perl(Compress::Raw::Zlib) >= 2.061 for package: perl-IO-Compress-2.061-2.el7.noarch
--> Processing Dependency: perl(Compress::Raw::Bzip2) >= 2.061 for package: perl-IO-Compress-2.061-2.el7.noarch
---> Package perl-Net-Daemon.noarch 0:0.48-5.el7 will be installed
---> Package perl-Pod-Escapes.noarch 1:1.04-283.el7 will be installed
---> Package perl-Pod-Perldoc.noarch 0:3.20-4.el7 will be installed
--> Processing Dependency: perl(parent) for package: perl-Pod-Perldoc-3.20-4.el7.noarch
--> Processing Dependency: perl(HTTP::Tiny) for package: perl-Pod-Perldoc-3.20-4.el7.noarch
---> Package perl-podlators.noarch 0:2.5.1-3.el7 will be installed
--> Running transaction check
---> Package perl-Compress-Raw-Bzip2.x86_64 0:2.061-3.el7 will be installed
---> Package perl-Compress-Raw-Zlib.x86_64 1:2.061-4.el7 will be installed
---> Package perl-HTTP-Tiny.noarch 0:0.033-3.el7 will be installed
---> Package perl-parent.noarch 1:0.225-244.el7 will be installed
--> Finished Dependency Resolution
Dependencies Resolved
==============================================================================================================================
Package Arch Version Repository Size
==============================================================================================================================
Installing:
mysql-community-libs x86_64 5.6.19-2.el7 mysql56-community 2.0 M
replacing mariadb-libs.x86_64 1:5.5.37-1.el7_0
mysql-community-server x86_64 5.6.19-2.el7 mysql56-community 57 M
Installing for dependencies:
libaio x86_64 0.3.109-12.el7 base 24 k
mysql-community-client x86_64 5.6.19-2.el7 mysql56-community 19 M
mysql-community-common x86_64 5.6.19-2.el7 mysql56-community 247 k
net-tools x86_64 2.0-0.17.20131004git.el7 base 304 k
perl x86_64 4:5.16.3-283.el7 base 8.0 M
perl-Carp noarch 1.26-244.el7 base 19 k
perl-Compress-Raw-Bzip2 x86_64 2.061-3.el7 base 32 k
perl-Compress-Raw-Zlib x86_64 1:2.061-4.el7 base 57 k
perl-DBI x86_64 1.627-4.el7 base 802 k
perl-Data-Dumper x86_64 2.145-3.el7 base 47 k
perl-Encode x86_64 2.51-7.el7 base 1.5 M
perl-Exporter noarch 5.68-3.el7 base 28 k
perl-File-Path noarch 2.09-2.el7 base 26 k
perl-File-Temp noarch 0.23.01-3.el7 base 56 k
perl-Filter x86_64 1.49-3.el7 base 76 k
perl-Getopt-Long noarch 2.40-2.el7 base 56 k
perl-HTTP-Tiny noarch 0.033-3.el7 base 38 k
perl-IO-Compress noarch 2.061-2.el7 base 260 k
perl-Net-Daemon noarch 0.48-5.el7 base 51 k
perl-PathTools x86_64 3.40-5.el7 base 82 k
perl-PlRPC noarch 0.2020-14.el7 base 36 k
perl-Pod-Escapes noarch 1:1.04-283.el7 base 49 k
perl-Pod-Perldoc noarch 3.20-4.el7 base 87 k
perl-Pod-Simple noarch 1:3.28-4.el7 base 216 k
perl-Pod-Usage noarch 1.63-3.el7 base 27 k
perl-Scalar-List-Utils x86_64 1.27-248.el7 base 36 k
perl-Socket x86_64 2.010-3.el7 base 49 k
perl-Storable x86_64 2.45-3.el7 base 77 k
perl-Text-ParseWords noarch 3.29-4.el7 base 14 k
perl-Time-Local noarch 1.2300-2.el7 base 24 k
perl-constant noarch 1.27-2.el7 base 19 k
perl-libs x86_64 4:5.16.3-283.el7 base 686 k
perl-macros x86_64 4:5.16.3-283.el7 base 42 k
perl-parent noarch 1:0.225-244.el7 base 12 k
perl-podlators noarch 2.5.1-3.el7 base 112 k
perl-threads x86_64 1.87-4.el7 base 49 k
perl-threads-shared x86_64 1.43-6.el7 base 39 k
Transaction Summary
==============================================================================================================================
Install 2 Packages (+37 Dependent packages)
Total download size: 91 M
Is this ok [y/d/N]: y
Downloading packages:
warning: /var/cache/yum/x86_64/7/mysql56-community/packages/mysql-community-common-5.6.19-2.el7.x86_64.rpm: V3 DSA/SHA1 Signature, key ID 5072e1f5: NOKEY
Public key for mysql-community-common-5.6.19-2.el7.x86_64.rpm is not installed
(1/39): mysql-community-common-5.6.19-2.el7.x86_64.rpm | 247 kB 00:00:01
(2/39): libaio-0.3.109-12.el7.x86_64.rpm | 24 kB 00:00:03
(3/39): mysql-community-libs-5.6.19-2.el7.x86_64.rpm | 2.0 MB 00:00:05
(4/39): perl-Carp-1.26-244.el7.noarch.rpm | 19 kB 00:00:02
(5/39): perl-Compress-Raw-Bzip2-2.061-3.el7.x86_64.rpm | 32 kB 00:00:01
(6/39): net-tools-2.0-0.17.20131004git.el7.x86_64.rpm | 304 kB 00:00:04
(7/39): perl-Compress-Raw-Zlib-2.061-4.el7.x86_64.rpm | 57 kB 00:00:01
(8/39): perl-Data-Dumper-2.145-3.el7.x86_64.rpm | 47 kB 00:00:01
(9/39): perl-DBI-1.627-4.el7.x86_64.rpm | 802 kB 00:00:03
(10/39): perl-Exporter-5.68-3.el7.noarch.rpm | 28 kB 00:00:00
(11/39): perl-File-Path-2.09-2.el7.noarch.rpm | 26 kB 00:00:00
(12/39): perl-File-Temp-0.23.01-3.el7.noarch.rpm | 56 kB 00:00:00
(13/39): perl-Filter-1.49-3.el7.x86_64.rpm | 76 kB 00:00:00
(14/39): perl-Getopt-Long-2.40-2.el7.noarch.rpm | 56 kB 00:00:00
(15/39): perl-HTTP-Tiny-0.033-3.el7.noarch.rpm | 38 kB 00:00:00
(16/39): perl-IO-Compress-2.061-2.el7.noarch.rpm | 260 kB 00:00:01
(17/39): perl-Encode-2.51-7.el7.x86_64.rpm | 1.5 MB 00:00:08
(18/39): perl-Net-Daemon-0.48-5.el7.noarch.rpm | 51 kB 00:00:03
(19/39): perl-PlRPC-0.2020-14.el7.noarch.rpm | 36 kB 00:00:00
(20/39): perl-Pod-Escapes-1.04-283.el7.noarch.rpm | 49 kB 00:00:00
(21/39): perl-Pod-Perldoc-3.20-4.el7.noarch.rpm | 87 kB 00:00:01
(22/39): perl-Pod-Simple-3.28-4.el7.noarch.rpm | 216 kB 00:00:02
(23/39): perl-Pod-Usage-1.63-3.el7.noarch.rpm | 27 kB 00:00:00
(24/39): perl-Scalar-List-Utils-1.27-248.el7.x86_64.rpm | 36 kB 00:00:00
(25/39): perl-Socket-2.010-3.el7.x86_64.rpm | 49 kB 00:00:00
(26/39): perl-Storable-2.45-3.el7.x86_64.rpm | 77 kB 00:00:00
(27/39): perl-Text-ParseWords-3.29-4.el7.noarch.rpm | 14 kB 00:00:00
(28/39): perl-Time-Local-1.2300-2.el7.noarch.rpm | 24 kB 00:00:00
(29/39): perl-constant-1.27-2.el7.noarch.rpm | 19 kB 00:00:00
(30/39): perl-PathTools-3.40-5.el7.x86_64.rpm | 82 kB 00:00:12
(31/39): perl-libs-5.16.3-283.el7.x86_64.rpm | 686 kB 00:00:03
(32/39): perl-parent-0.225-244.el7.noarch.rpm | 12 kB 00:00:00
(33/39): perl-podlators-2.5.1-3.el7.noarch.rpm | 112 kB 00:00:00
(34/39): perl-threads-1.87-4.el7.x86_64.rpm | 49 kB 00:00:00
(35/39): perl-threads-shared-1.43-6.el7.x86_64.rpm | 39 kB 00:00:00
(36/39): perl-macros-5.16.3-283.el7.x86_64.rpm | 42 kB 00:00:05
(37/39): mysql-community-client-5.6.19-2.el7.x86_64.rpm | 19 MB 00:00:57
(38/39): perl-5.16.3-283.el7.x86_64.rpm | 8.0 MB 00:01:13
(39/39): mysql-community-server-5.6.19-2.el7.x86_64.rpm | 57 MB 00:01:35
------------------------------------------------------------------------------------------------------------------------------
Total 915 kB/s | 91 MB 00:01:41
Retrieving key from file:/etc/pki/rpm-gpg/RPM-GPG-KEY-mysql
Importing GPG key 0x5072E1F5:
Userid : "MySQL Release Engineering "
Fingerprint: a4a9 4068 76fc bd3c 4567 70c8 8c71 8d3b 5072 e1f5
Package : mysql-community-release-el7-5.noarch (@/mysql-community-release-el7-5.noarch)
From : file:/etc/pki/rpm-gpg/RPM-GPG-KEY-mysql
Is this ok [y/N]: y
Running transaction check
Running transaction test
Transaction test succeeded
Running transaction
Installing : mysql-community-common-5.6.19-2.el7.x86_64 1/40
Installing : mysql-community-libs-5.6.19-2.el7.x86_64 2/40
Installing : 1:perl-parent-0.225-244.el7.noarch 3/40
Installing : perl-HTTP-Tiny-0.033-3.el7.noarch 4/40
Installing : perl-podlators-2.5.1-3.el7.noarch 5/40
Installing : perl-Pod-Perldoc-3.20-4.el7.noarch 6/40
Installing : 1:perl-Pod-Escapes-1.04-283.el7.noarch 7/40
Installing : perl-Text-ParseWords-3.29-4.el7.noarch 8/40
Installing : perl-Encode-2.51-7.el7.x86_64 9/40
Installing : perl-Pod-Usage-1.63-3.el7.noarch 10/40
Installing : 4:perl-libs-5.16.3-283.el7.x86_64 11/40
Installing : 4:perl-macros-5.16.3-283.el7.x86_64 12/40
Installing : perl-Storable-2.45-3.el7.x86_64 13/40
Installing : perl-Exporter-5.68-3.el7.noarch 14/40
Installing : perl-constant-1.27-2.el7.noarch 15/40
Installing : perl-Time-Local-1.2300-2.el7.noarch 16/40
Installing : perl-Socket-2.010-3.el7.x86_64 17/40
Installing : perl-Carp-1.26-244.el7.noarch 18/40
Installing : perl-PathTools-3.40-5.el7.x86_64 19/40
Installing : perl-Scalar-List-Utils-1.27-248.el7.x86_64 20/40
Installing : perl-File-Temp-0.23.01-3.el7.noarch 21/40
Installing : perl-File-Path-2.09-2.el7.noarch 22/40
Installing : perl-threads-shared-1.43-6.el7.x86_64 23/40
Installing : perl-threads-1.87-4.el7.x86_64 24/40
Installing : perl-Filter-1.49-3.el7.x86_64 25/40
Installing : 1:perl-Pod-Simple-3.28-4.el7.noarch 26/40
Installing : perl-Getopt-Long-2.40-2.el7.noarch 27/40
Installing : 4:perl-5.16.3-283.el7.x86_64 28/40
Installing : perl-Data-Dumper-2.145-3.el7.x86_64 29/40
Installing : perl-Compress-Raw-Bzip2-2.061-3.el7.x86_64 30/40
Installing : perl-Net-Daemon-0.48-5.el7.noarch 31/40
Installing : mysql-community-client-5.6.19-2.el7.x86_64 32/40
Installing : 1:perl-Compress-Raw-Zlib-2.061-4.el7.x86_64 33/40
Installing : perl-IO-Compress-2.061-2.el7.noarch 34/40
Installing : perl-PlRPC-0.2020-14.el7.noarch 35/40
Installing : perl-DBI-1.627-4.el7.x86_64 36/40
Installing : libaio-0.3.109-12.el7.x86_64 37/40
Installing : net-tools-2.0-0.17.20131004git.el7.x86_64 38/40
Installing : mysql-community-server-5.6.19-2.el7.x86_64 39/40
Erasing : 1:mariadb-libs-5.5.37-1.el7_0.x86_64 40/40
Verifying : perl-HTTP-Tiny-0.033-3.el7.noarch 1/40
Verifying : perl-threads-shared-1.43-6.el7.x86_64 2/40
Verifying : perl-Storable-2.45-3.el7.x86_64 3/40
Verifying : net-tools-2.0-0.17.20131004git.el7.x86_64 4/40
Verifying : perl-Exporter-5.68-3.el7.noarch 5/40
Verifying : perl-constant-1.27-2.el7.noarch 6/40
Verifying : perl-PathTools-3.40-5.el7.x86_64 7/40
Verifying : 4:perl-5.16.3-283.el7.x86_64 8/40
Verifying : libaio-0.3.109-12.el7.x86_64 9/40
Verifying : mysql-community-server-5.6.19-2.el7.x86_64 10/40
Verifying : 1:perl-parent-0.225-244.el7.noarch 11/40
Verifying : perl-Compress-Raw-Bzip2-2.061-3.el7.x86_64 12/40
Verifying : perl-Net-Daemon-0.48-5.el7.noarch 13/40
Verifying : 1:perl-Pod-Simple-3.28-4.el7.noarch 14/40
Verifying : perl-File-Temp-0.23.01-3.el7.noarch 15/40
Verifying : 4:perl-libs-5.16.3-283.el7.x86_64 16/40
Verifying : perl-Time-Local-1.2300-2.el7.noarch 17/40
Verifying : mysql-community-libs-5.6.19-2.el7.x86_64 18/40
Verifying : perl-Pod-Perldoc-3.20-4.el7.noarch 19/40
Verifying : perl-DBI-1.627-4.el7.x86_64 20/40
Verifying : perl-Socket-2.010-3.el7.x86_64 21/40
Verifying : 4:perl-macros-5.16.3-283.el7.x86_64 22/40
Verifying : mysql-community-client-5.6.19-2.el7.x86_64 23/40
Verifying : perl-Carp-1.26-244.el7.noarch 24/40
Verifying : perl-Data-Dumper-2.145-3.el7.x86_64 25/40
Verifying : perl-Scalar-List-Utils-1.27-248.el7.x86_64 26/40
Verifying : 1:perl-Compress-Raw-Zlib-2.061-4.el7.x86_64 27/40
Verifying : perl-IO-Compress-2.061-2.el7.noarch 28/40
Verifying : perl-Pod-Usage-1.63-3.el7.noarch 29/40
Verifying : perl-PlRPC-0.2020-14.el7.noarch 30/40
Verifying : perl-Encode-2.51-7.el7.x86_64 31/40
Verifying : perl-podlators-2.5.1-3.el7.noarch 32/40
Verifying : perl-Getopt-Long-2.40-2.el7.noarch 33/40
Verifying : perl-File-Path-2.09-2.el7.noarch 34/40
Verifying : perl-threads-1.87-4.el7.x86_64 35/40
Verifying : perl-Filter-1.49-3.el7.x86_64 36/40
Verifying : 1:perl-Pod-Escapes-1.04-283.el7.noarch 37/40
Verifying : perl-Text-ParseWords-3.29-4.el7.noarch 38/40
Verifying : mysql-community-common-5.6.19-2.el7.x86_64 39/40
Verifying : 1:mariadb-libs-5.5.37-1.el7_0.x86_64 40/40
Installed:
mysql-community-libs.x86_64 0:5.6.19-2.el7 mysql-community-server.x86_64 0:5.6.19-2.el7
Dependency Installed:
libaio.x86_64 0:0.3.109-12.el7 mysql-community-client.x86_64 0:5.6.19-2.el7
mysql-community-common.x86_64 0:5.6.19-2.el7 net-tools.x86_64 0:2.0-0.17.20131004git.el7
perl.x86_64 4:5.16.3-283.el7 perl-Carp.noarch 0:1.26-244.el7
perl-Compress-Raw-Bzip2.x86_64 0:2.061-3.el7 perl-Compress-Raw-Zlib.x86_64 1:2.061-4.el7
perl-DBI.x86_64 0:1.627-4.el7 perl-Data-Dumper.x86_64 0:2.145-3.el7
perl-Encode.x86_64 0:2.51-7.el7 perl-Exporter.noarch 0:5.68-3.el7
perl-File-Path.noarch 0:2.09-2.el7 perl-File-Temp.noarch 0:0.23.01-3.el7
perl-Filter.x86_64 0:1.49-3.el7 perl-Getopt-Long.noarch 0:2.40-2.el7
perl-HTTP-Tiny.noarch 0:0.033-3.el7 perl-IO-Compress.noarch 0:2.061-2.el7
perl-Net-Daemon.noarch 0:0.48-5.el7 perl-PathTools.x86_64 0:3.40-5.el7
perl-PlRPC.noarch 0:0.2020-14.el7 perl-Pod-Escapes.noarch 1:1.04-283.el7
perl-Pod-Perldoc.noarch 0:3.20-4.el7 perl-Pod-Simple.noarch 1:3.28-4.el7
perl-Pod-Usage.noarch 0:1.63-3.el7 perl-Scalar-List-Utils.x86_64 0:1.27-248.el7
perl-Socket.x86_64 0:2.010-3.el7 perl-Storable.x86_64 0:2.45-3.el7
perl-Text-ParseWords.noarch 0:3.29-4.el7 perl-Time-Local.noarch 0:1.2300-2.el7
perl-constant.noarch 0:1.27-2.el7 perl-libs.x86_64 4:5.16.3-283.el7
perl-macros.x86_64 4:5.16.3-283.el7 perl-parent.noarch 1:0.225-244.el7
perl-podlators.noarch 0:2.5.1-3.el7 perl-threads.x86_64 0:1.87-4.el7
perl-threads-shared.x86_64 0:1.43-6.el7
Replaced:
mariadb-libs.x86_64 1:5.5.37-1.el7_0
Complete!
As you can see, the community server package defaults to the latest version of MySQL 5.6. During the installation process, only two interruptions may happen (aside from the sudo password), one for confirmation of changes, and another to import the Oracle release engineers’ key on your system, which should be fine if it matches the fingerprint a4a9 4068 76fc bd3c 4567 70c8 8c71 8d3b 5072 e1f5. Remember that for automatic processes, we can give the -y (assume yes to all) flag to yum, but I wanted to avoid that for explanation and security purposes.
We are done with the installation, now we only have to run it and test it. Remember that Red Hat Enterprise Linux 7 replaces the management of services with systemd, so the “correct” way of starting the mysql service is:
$ sudo systemctl start mysqld
You can check that it started successfully by doing:
$ sudo systemctl status mysqld
mysqld.service - MySQL Community Server
Loaded: loaded (/usr/lib/systemd/system/mysqld.service; disabled)
Active: active (running) since Sun 2014-07-27 11:20:40 EDT; 10s ago
Process: 10660 ExecStartPost=/usr/bin/mysql-systemd-start post (code=exited, status=0/SUCCESS)
Process: 10599 ExecStartPre=/usr/bin/mysql-systemd-start pre (code=exited, status=0/SUCCESS)
Main PID: 10659 (mysqld_safe)
CGroup: /system.slice/mysqld.service
├─10659 /bin/sh /usr/bin/mysqld_safe
└─10801 /usr/sbin/mysqld --basedir=/usr --datadir=/var/lib/mysql --plugin-dir=/usr/lib64/mysql/plugin --log-erro...
Jul 27 11:20:39 localhost.localdomain mysql-systemd-start[10599]: Support MySQL by buying support/licenses at http://sho...com
Jul 27 11:20:39 localhost.localdomain mysql-systemd-start[10599]: Note: new default config file not created.
Jul 27 11:20:39 localhost.localdomain mysql-systemd-start[10599]: Please make sure your config file is current
Jul 27 11:20:39 localhost.localdomain mysql-systemd-start[10599]: WARNING: Default config file /etc/my.cnf exists on the...tem
Jul 27 11:20:39 localhost.localdomain mysql-systemd-start[10599]: This file will be read by default by the MySQL server
Jul 27 11:20:39 localhost.localdomain mysql-systemd-start[10599]: If you do not want to use this, either remove it, or use the
Jul 27 11:20:39 localhost.localdomain mysql-systemd-start[10599]: --defaults-file argument to mysqld_safe when starting ...ver
Jul 27 11:20:39 localhost.localdomain mysqld_safe[10659]: 140727 11:20:39 mysqld_safe Logging to '/var/log/mysqld.log'.
Jul 27 11:20:39 localhost.localdomain mysqld_safe[10659]: 140727 11:20:39 mysqld_safe Starting mysqld daemon with datab...ysql
Jul 27 11:20:40 localhost.localdomain systemd[1]: Started MySQL Community Server.
Hint: Some lines were ellipsized, use -l to show in full.
And now connect from localhost by doing:
$ mysql -u root
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.6.19 MySQL Community Server (GPL)
Copyright (c) 2000, 2014, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
Remember also to activate the mysql auto-start on boot, as you will want in most cases (this has also changed from CentOS 6):
You can check that it was enabled successfully with the previously shown ‘status’ command; it should be shown now as “enabled”.
As good administrator, the next steps will be to properly configure user accounts and securize the database service, but that is out of the scope of this tutorial.
Thanks to installing via repository, now your packages can be easily upgraded by using yum.


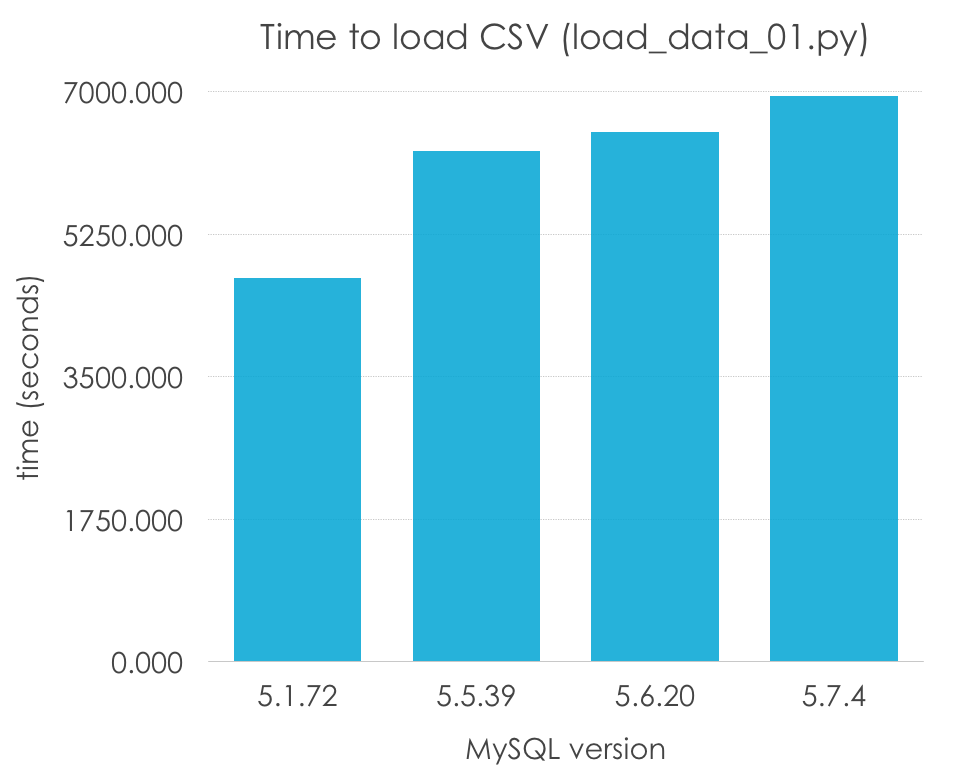
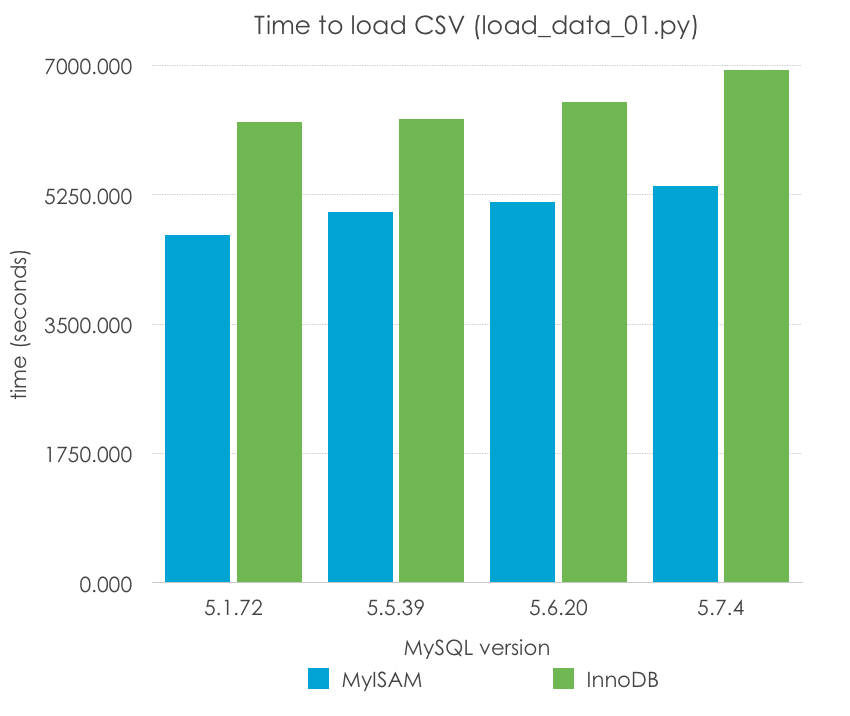
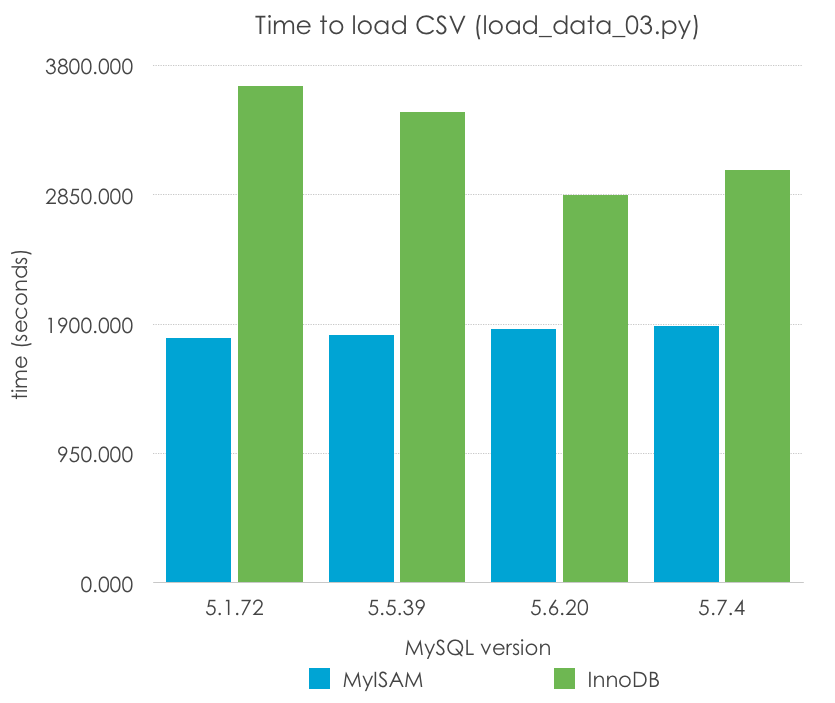
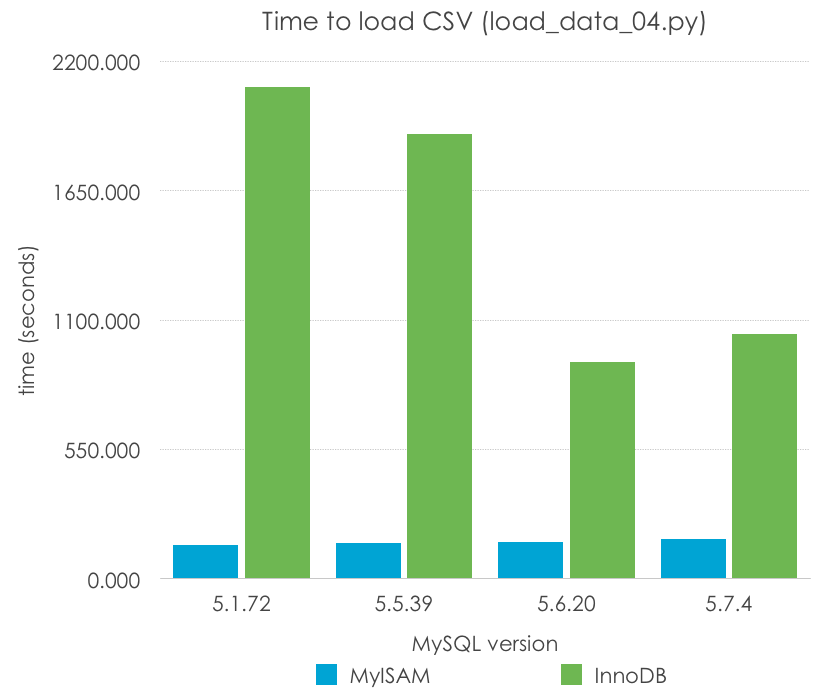
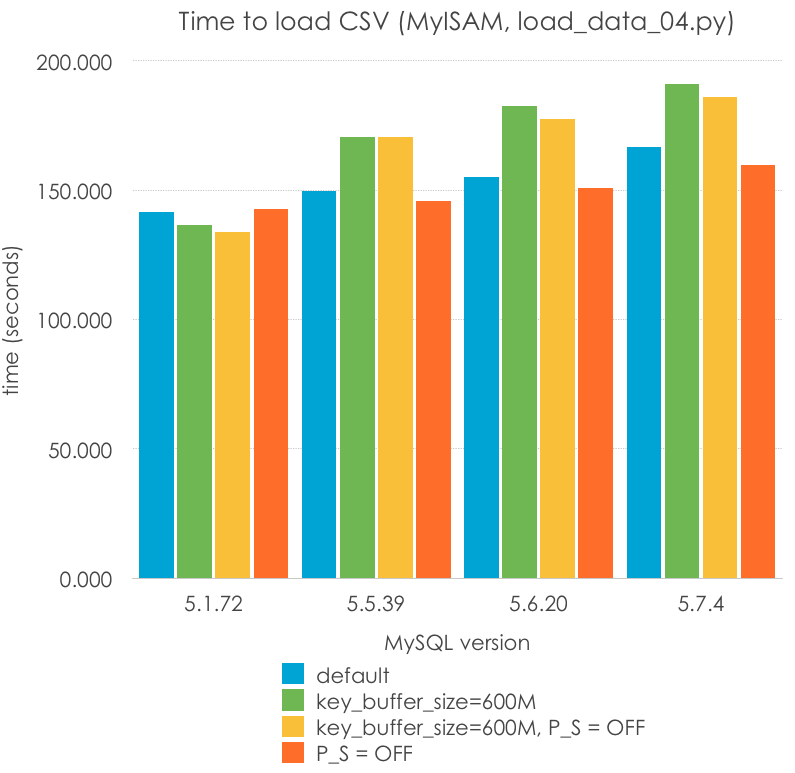


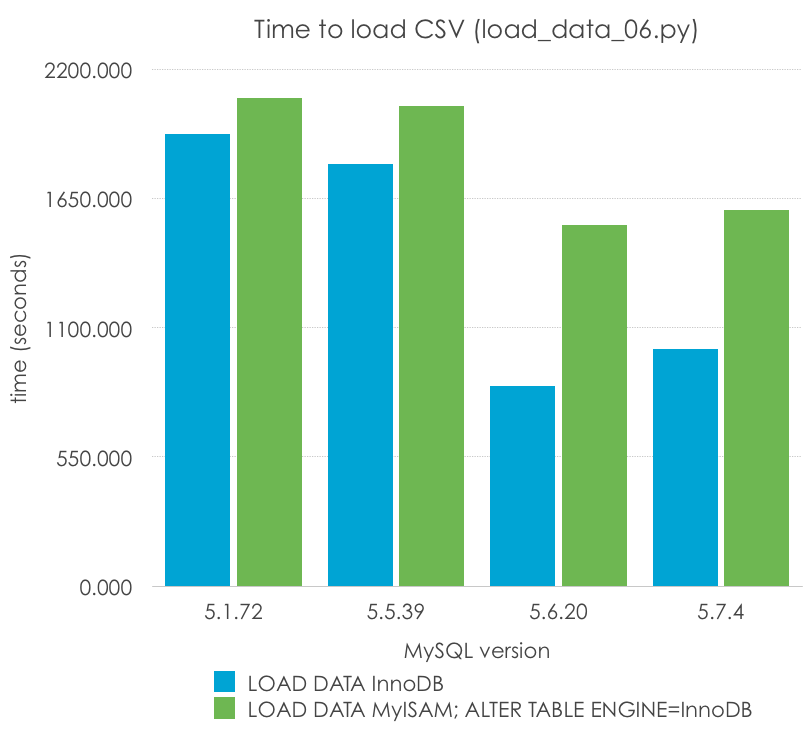
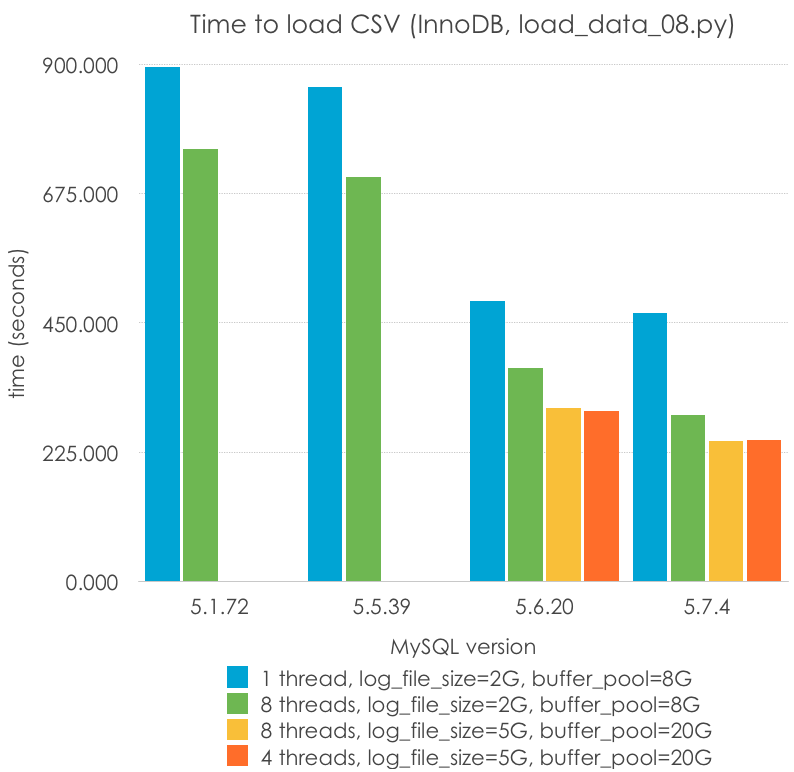


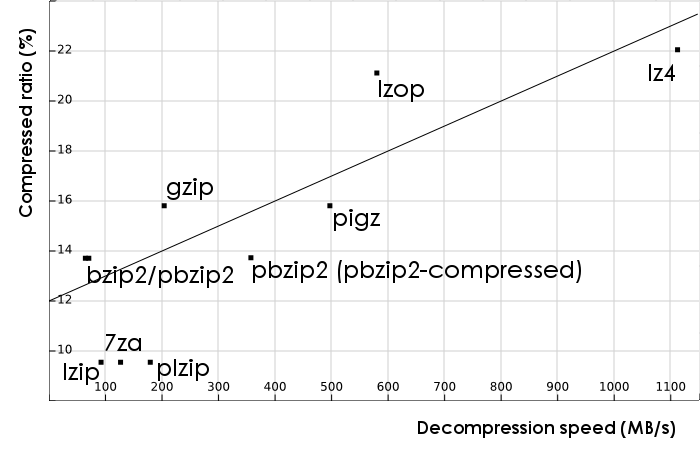


{kind=link}