
![]()
![]() I am happy that the MySQL team is, during the last years, blogging about each major feature that MySQL Server is getting; for example, the series on Recursive Common Table Expressions. Being extremely busy myself, I appreciate taking the time to share details with the advantage of getting an “insider” point of view.
I am happy that the MySQL team is, during the last years, blogging about each major feature that MySQL Server is getting; for example, the series on Recursive Common Table Expressions. Being extremely busy myself, I appreciate taking the time to share details with the advantage of getting an “insider” point of view.
However, first party guides and examples can be seen at times as not terrible useful at first- as normally they are done with synthetic, artificial examples and not real-life ones. I want to share with you 2 examples of how 2 of the upcoming features of MySQL 8.0 will be useful to us, with examples that we already use or plan to use for the Wikimedia Foundation databases: roles and recursive CTEs.
Roles
 Giusseppe “data charmer” Maxia presented recently at FOSDEM 2018 how the newly introduced roles are going work (you can watch and read his presentation at the FOSDEM website) and he seemed quite skeptical about the operational side of it. I have to agree -some of the details are not straightforward as how users and roles work on other environments, but I have to say we have been using database roles for a while with MariaDB without any problems in the last year.
Giusseppe “data charmer” Maxia presented recently at FOSDEM 2018 how the newly introduced roles are going work (you can watch and read his presentation at the FOSDEM website) and he seemed quite skeptical about the operational side of it. I have to agree -some of the details are not straightforward as how users and roles work on other environments, but I have to say we have been using database roles for a while with MariaDB without any problems in the last year.
User roles were introduced on MariaDB 10.0, although for us they were unusable until MariaDB 10.1, and its implementation seems to be similar, if not exactly the same as that of MySQL 8.0 (side note. I do not know why that is ̣—is it an SQL standard? Was the implementation inspired by Oracle or other famous database? does it have a common origin? Please tell me in the comments if you know the answer).
If you use MySQL for a single large web-like application, roles may not be very useful to you. For example, for the Mediawiki installation that supports Wikipedia, only a few accounts are setup per database server -one or a few for the application, plus those needed for monitoring, backups and administration (please do not use a single root account for all in yours!).
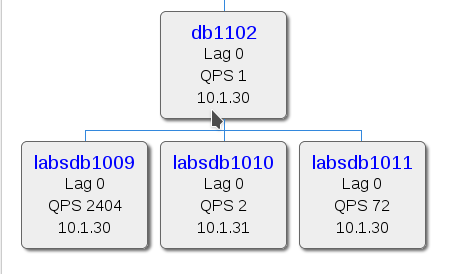
However, we also provide free hosting and other IT services for all developers (including volunteers) to create webs, applications and gadgets that could be useful to the full Wikimedia community. Among those services, we have a data service where we provide a replica of a sanitized database with most of the data of the production mediawiki installation, plus additional database accounts to store their own application data. This requires a highly multi-tiered MySQL/MariaDB installation, with thousands of accounts per server. In the past, each account had to be managed separately, with its own grants and accounts limits- this was a nightmare, and the little accountability could easily lead to security issues. Wildcards were used to assign grants, which was a really bad idea- because wildcards not only provide grants to current databases, also to future databases that match the pattern- and that is very dangerous- wrong data sets could accidentally end up on the wrong servers and all users would get automatically access. Also, every time there was some kind of maintenance where all users had to be added or revoked certain grant (not frequent, but could happen), a script had to be run to do that in a loop for each account. Also, there are other accounts aside from user accounts (the administration and monitoring ones), but aside from a specific string pattern, there was no way to differentiate user from administration or monitoring accounts.
Our cloud databases were the first we upgraded to MariaDB 10.1 exclusively to get a transparent role implementation (SET default role). We created a template role (e.g. ‘labsdbuser‘), which all normal users will be granted to (you can see the actual code on our puppet repo):
GRANT USAGE ON *.* TO...; GRANT labsdbuser TO ; SET DEFAULT ROLE labsdbuser FOR ;
, and because it is so compact, we can give a detailed, non-wildcard-based selection of grants to to the labsdbuser generic role.
If we had to add a new grant (or revoke it) to all users, we just have to run:
GRANT/ REVOKETO / FROM labsdbuser;
only once per server, and all users affected will get it automatically (well, they have to log off and on, but that was true of any grant).
Can the syntax be simpler or the underlying tables confusing? Sure, but in practice -at least for us-, we rarely have to handle role changes- they don’t tend to be very dynamic. However, it simplified a lot the creation, accountability, monitoring and administration of user accounts for us.
Recursive CTEs
CTEs are one of the other large syntactic sugar added on 8.0 (they were also added on MariaDB 10.2). Unlike the roles, however, this is something that application developers will benefit from -roles are mostly helpful for Database Administrators.
As I mentioned before, we have upgraded our servers at most to MariaDB 10.1 (stability is very important for us), so I have not yet been able to play on production with them. Also, because Mediawiki has to support older applications, it might take years to see those being used on web requests for wikis. I see them, however, being interesting first for analytics and for the cloud community applications I mentioned previously.
Mediawiki has some hierarchical data stored on their tables; probably the most infamous one is the category tree. As of 2018 (this may change in the future), the main way to group Wiki pages and files is by using categories. However, unlike the concept of tags, categories may contain other more specialized categories.
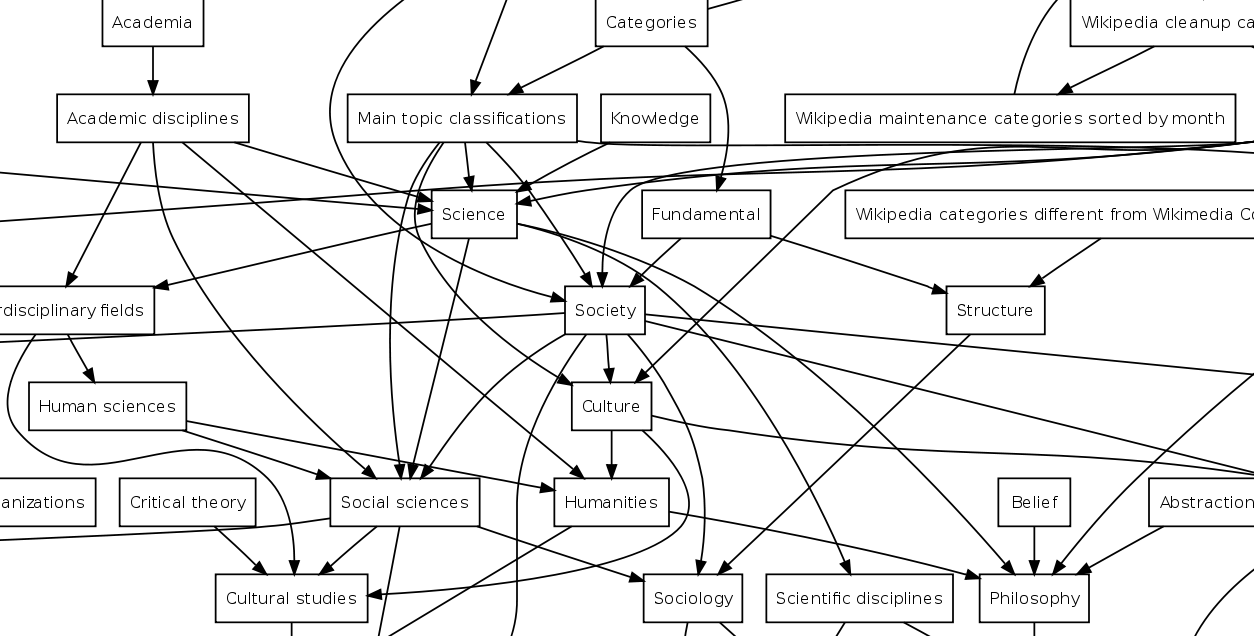
Image License: CC-BY-SA-3.0 Author: Gurch at English Wikipedia
{kind=link}
For example, the [[MySQL]] article has the following categories:
- 1995 software
- Client-server database management systems
- Cross-platform software
- Free database management systems
- MySQL
- Oracle software
- RDBMS software for Linux
- Relational database management systems
- Sun Microsystems software
- (Plus other hidden ones coming from templates)
(You can obtain a real time list with a Mediawiki API call, too)
However, if you go to the category Database management systems, you will not find it there, because you have to browse first thought Database management systems > Relational database management systems > MySQL; or maybe Database management systems > Database-related software for Linux > RDBMS software for Linux > MySQL
The relationship between pages and categories are handled on the classical “(parent, child) table” fashion, the categorylinks table, which has the following structure:
CREATE TABLE /*_*/categorylinks ( -- Key to page_id of the page defined as a category member. cl_from int unsigned NOT NULL default 0, -- Name of the category. -- This is also the page_title of the category's description page; -- all such pages are in namespace 14 (NS_CATEGORY). cl_to varchar(255) binary NOT NULL default '', ... PRIMARY KEY (cl_from,cl_to) ) /*$wgDBTableOptions*/; CREATE INDEX /*i*/cl_sortkey ON /*_*/categorylinks (cl_to,cl_type,cl_sortkey,cl_from);
The table has been simplified, we will not get on this post into collation issues- that would be material for other separate discussion. Also ignore the fact that cl_to links to a binary string rather than an id, there are reasons for all of that, but cannot enter into details now.
If you want to play with the real thing, you can download it from here, it is, as of February 2018, only 2GB compressed: https://dumps.wikimedia.org/enwiki/latest/enwiki-latest-categorylinks.sql.gz
This table structure works nicely to answer questions like:
- “Which articles and subcategories are directly on a given category (Database_management_systems)?”
SELECT IF(page_namespace = 14, 'category', 'article') as type, page_title FROM categorylinks JOIN page ON page_id = cl_from WHERE cl_to = 'Database_management_systems'
You can see the live results of this query.
- “Which categories does a particular article (MySQL) contain?”
SELECT cl_to FROM categorylinks JOIN page ON page_id = cl_from WHERE page_namespace = 0 AND page_title = 'MySQL';
You can see the live results of this query.
However, if you want to answer the question “Give me all articles in a particular category or its subcategories”, this structure is not well suited to answer this question. Or at least it didn’t use to be, for older versions of MySQL and MariaDB. Alternative table design structures have been proposed in the past (both for Mediawiki and for the general problem) to solve this commonly found structure, but not all will be a applicable, as the Wiki category system is very flexible, and not even strictly a tree- it can contain, for example, loops.
Up to now, custom solutions, such as this answer on stackoverflow, or specially-built applications, such as: Petscan, had to be developed to provide lists of articles queried recursively.
Again, enter recursive CTEs. Instead of having to use external code to apply recursion, or an awkward stored procedure, we can just send the following sql:
WITH RECURSIVE cte (cl_from, cl_type) AS
(
SELECT cl_from, cl_type FROM categorylinks WHERE cl_to = 'Database_management_systems' -- starting category
UNION
SELECT categorylinks.cl_from, categorylinks.cl_type FROM cte JOIN page ON cl_from = page_id JOIN categorylinks ON page_title = cl_to WHERE cte.cl_type = 'subcat' -- subcat addition on each iteration
)
SELECT page_title FROM cte JOIN page ON cl_from = page_id WHERE page_namespace = 0 ORDER BY page_title; -- printing only articles in the end, ordered by title
With results:
+-------------------------------------------------------------+ | page_title | +-------------------------------------------------------------+ | 4th_Dimension_(software) | | A+_(programming_language) | | ABC_(programming_language) | | ACID | | ADABAS | | ADO.NET | | ADOdb | | ADOdb_Lite | | ADSO | | ANSI-SPARC_Architecture | | Adabas_D | | Adaptive_Server_Enterprise | ... | Yellowfin_Business_Intelligence | | Zope_Object_Database | +-------------------------------------------------------------+ 511 rows in set (0.02 sec)
It looks more complicated than it should, because we need to join with the page table in order to get page ids from titles; but otherwise the idea is simple: get a list of pages, if they are subcategories, query them recursively, otherwise, add them to the list. By using UNION instead of UNION ALL we make sure we do not explore the same subcategory twice. Note how we end up with a list larger than the 143 items are directly on the category.
If we fall in an infinite loop, or a very deep chain of relationships, the variable limiting the number of executions, cte_max_recursion_depth can be tuned. By default it fails if we do 1001 iterations.
I don’t intend to provide an in depth guide about CTEs, check the 8.0 manual for more information and the above mentioned MySQL Team blog posts.
So tell me, do you think these or other recently-added features will be as useful for you as the seem to be for us? What is your favourite one recently added to MySQL or MariaDB? Send me a comment or a message to @jynus.