El “Concurso Universitario de Software Libre” (CUSL) es una iniciativa similar a la del Google Summer of Code, pero específicamente dirigida la comunidad universitaria y de estudiantes de bachillerato españoles y organizada por una grupo de Oficinas de software libre de universidades.
Como parte del esfuerzo para promover el crecimiento del ecosistema del software libre, así como introducir a talento joven en el desarrollo de aplicaciones y tecnologías libres, DBAHire.com acaba de convertirse en patrocinador plata de la competición, proporcionando recursos para los premios, gastos de desplazamiento y alojamiento de los estudiantes.
La fase final de la competición tendrá lugar el próximo 7-8 de Mayo en Zaragoza, y nuestro consultor MySQL Jaime Crespo impartirá ese viernes una pequeña charla titulada “Software libre ¿es rentable?”.
Una sirena tiene las mismas probabilidades de arreglar tus problemas de permisos, la diferencia es que la gente continúa creyendo en el mito de FLUSH PRIVILEGES.
Cada vez que alguien escribe un tutorial o solución a un problema relacionado con la creación de una nueva cuentas de usuario o la provisión de diferentes privilegios veo la sugerencia de utilizar FLUSH PRIVILEGES. Por ejemplo, el primer post en /r/mysql en el momento de escribir estas líneas, “MySQL:The user specified as a definer does not exist (error 1449)-Solutions” es culpable múltiples veces de esto mismo (Actualización: el usuario ha tachado estas líneas, tras la publicación de este artículo).
No es mi intención denunciar ese artículo, pero lo cierto es que he visto cometer ese error muchas, muchas veces. Incluso si os dirigís a la página del manual de referencia sobre el comando GRANT veréis al final -de un usuario ajeno a MySQL- usar GRANT seguido de un FLUSH PRIVILEGES.
¿Por qué debería importarme? ¿Es FLUSH PRIVILEGES un problema? ¿Por qué lo hace todo el mundo? La razón de que ese comando exista es porque —para mejorar el rendimiento— MySQL mantiene una copia en memoria de las tablas GRANT (de permisos de usuario). De esta manera, no necesita leerlas de disco en cada conexión, en cada cambio de la base de datos por defecto, y en cada consulta enviada al servidor. El comando mencionado anteriormente fuerza la recarga de esta caché, leyéndola directamente de disco (o de la caché del sistema de archivos), tal y como el manual de referencia de MySQL indica claramente (teniendo incluso su propia sección When Privilege Changes Take Effect “Cuándo tienen efecto los cambios de privilegios”). Sin embargo, su ejecución es totalmente innecesaria en la mayoría de los casos prácticos porque:
If you modify the grant tables indirectly using account-management statements such as GRANT, REVOKE, SET PASSWORD, or RENAME USER, the server notices these changes and loads the grant tables into memory again immediately.
que significa, más o menos:
Si modificas las tablas de privilegios de manera inderecta, usando sentencias de gestión de cuentas tales como GRANT, REVOKE, SET PASSWORD o RENAME USER el servidor tiene en cuenta estos cambios y carga las tablas en memoria de nuevo de manera inmediata.
La única razón en la cual es necesario realizar la operación de recarga manualmente es cuando:
you modify the grant tables directly using statements such as INSERT, UPDATE, or DELETE (se modifican las tablas de privilegios directamente usando sentencias como INSERT, UPDATE o DELETE)
Para la mayoría de operaciones, como crear un usuario, cambiar sus privilegios o contraseña, es preferible usar las operaciones de alto nivel. No sólo son más fáciles de usar, también son en general compatibles con un mayor número de versiones de MySQL y además te evitarán cometer errores (por supuesto, es necesario acordarse de configurar el modo sql “NO_AUTO_CREATE_USER“). Incluso normalmente funcionarán sin problemas en un entorno hostil para MyISAM como es un clúster de Galera. Ciertamente, hay razones por las que puede ser necesario editar las tablas manualmente- como administradores, es posible que deseemos manipular de manera especial los privilegios o importar las tablas mysql.* de algún otro lugar, por lo que en estos casos ejecutar FLUSH PRIVILEGES es obligatorio. Tened en cuenta que, como dice la página del manual, en la mayoría de los casos (por ejemplo, privilegios globales) cambiar los permisos de un usuario sólo afectará a nuevas conexiones y nunca a consultas que se estén ejecutando ya que los privilegios se comprueban al inicio del procesado de la consulta -léase el manual para los detalles.
Así, pues, ¿por qué mi cruzada contra el abuso de FLUSH PRIVILEGES? Después de todo, en el peor de los casos, ¡se recargarán los mismos privilegios de nuevo! No es una cuestión de rendimiento. Aunque, en casos extremos bien podría ser un problema. Echad un vistazo al siguiente script, que ejecuta 10 000 sentencias CREATE USER (esto sólo se puede hacer en un único hilo ya que las tablas grant todavía están en formato MyISAM, incluso en 5.7.6):
def execute_test(port, drop, flush, thread):
db = mysql.connector.connect(host="localhost", port=port, user="msandbox", passwd="msandbox", database="test")
for i in range(0, TIMES):
cursor = db.cursor()
if (drop):
sql = "DROP USER 'test-" + `thread` + '-' + `i` + "'@'localhost'"
else:
sql = "CREATE USER 'test-" + `thread` + '-' + `i` + "'@'localhost' IDENTIFIED BY '" + DEFAULT_PASSWORD + "'"
cursor.execute(sql)
cursor.close()
db.commit()
if (flush):
cursor = db.cursor()
flush_sql = "FLUSH PRIVILEGES"
cursor.execute(flush_sql)
cursor.close()
db.commit()
db.close()
Las mediciones de tiempos de ambas ejecuciones son las siguientes:
$ time ./test_flush.py
Not flushing
Executing the command 10000 times
real 0m15.508s
user 0m0.827s
sys 0m0.323s
$ ./test_flush.py -d
Not flushing
Dropping users
Executing the command 10000 times
$ time ./test_flush.py -f
Flushing after each create
Executing the command 10000 times
real 2m7.041s
user 0m2.482s
sys 0m0.771s
$ ./test_flush.py -d
Not flushing
Dropping users
Executing the command 10000 times
Podemos ver que usar FLUSH PRIVILEGES es 8 veces más lento que no utilizarlo. De nuevo, quiero enfatizar que el rendimiento no es el mayor de los problemas en esta situación, ya que la mayoría de las personas lo ejecutarían tan sólo una vez al final de cada bloque de comandos, por lo que no supondría una gran sobrecarga. Incluso si hay una mayor cantidad de operaciones de lectura de disco, debemos asumir que todo round trip a la base de datos, y todo commit requiere ciertos recursos extra, por lo que esto mismo se puede extrapolar a cualquier comando. Además, la concurrencia no suele ser un problema en la creación de cuentas de usuario, ya que la tabla mysql.user no es normalmente (o no debería) se muy dinámica.
El mayor problema contra el abuso de FLUSH PRIVILEGES es que la gente lo ejecuta sin comprender porqué lo hacen, y lo que realmente hace este comando. Cada vez que una persona tiene un problema con el sistema de privilegios de MySQL, el primer consejo dado es ejecutar dicha sentencia “por si acaso”. Si no os lo creéis, echad un vistazo rápido a respuestas en dba.stackexchange como esta, esta y esta (que he seleccionado entre las muchas existentes), cuyo usuario original no estaba alterando manualmente las tablas mysql.*. La problemática está en que la mayor parte de las veces el comando no hace absolutamente nada, y el problema subyace en la pobre comprensión del sistema de permisos de MySQL. Como dice el dicho en inglés- cuando tienes un martillo, todo problema parece un clavo. Los usuarios leen que esa es la manera adecuada de resolver problemas relacionados con permisos y pasan el “conocimiento” a otros usuarios, creando básicamente el equivalente a una mito urbano en el mundo MySQL.
Así pues, la siguiente vez que encuentres un problema como un usuario que no puede entrar en la base de datos, o aplicarle privilegios, hay muchas otras fuentes de confusión, tales como: el uso de old_passwords, usar un método de autenticación distinto de las contraseñas nativas, no disponer de los permisos adecuados o de la propiedad WITH GRANT OPTION para transmitirlos, el servidor no detectando el usuario con el mismo nombre y host que en el que realmente está, el uso de skip-name-resolve lo qual hace que se ignores las entradas dns, no esperar a una nueva conexión para que los cambios surtan efecto, … y muchas otras dificultades que van unidas a la autenticación y autorización. El sistema de privilegios de MySQL no es precisamente obvio ni perfecto(¡Hola, otorgar permisos para bases de datos que no existen?), pero invertir 5 minutos en leer el detallado manual sobre grants puede ahorrar muchos quebraderos de cabeza en el futuro. TL;TR RTFM
Para aquellos que ya saben cuándo usar o no usar FLUSH PRIVILEGES, por favor, la siguiente vez que veáis a alguien abusarlo, educar al usuario sobre mejores prácticas para que la gente no siga fundamentándose en la magia y mitos urbanos para resolver problemas; id a reddit/stackoverflow/vuestra red social favorita/etc. y votad positivamente las buenas prácticas/comentad sobre las malas. Hoy podría ser FLUSH PRIVILEGES, mañana puede que sea “añadir OPTIMIZE TABLE en un trabajo del cron cada 5 minutos para tus tablas InnoDB” (y sí, esto último lo he encontrado en producción ahí fuera).
Aunque siempre deseamos un mayor rendimiento y más y mejores características para MySQL, estas no pueden aparecer “sin más” de una versión a otra, requiriendo profundos cambios en la arquitectura y muchas líneas de código. Sin embargo, a veces hay pequeños cambios y arreglos que podrían implementarse por un becario o contribuidor externo, principalmente en la capa SQL, que podrían hacer el ecosistema de MySQL más amigable para novatos y no expertos. Hacer que un programa sea más fácil de usar es muchas veces pasado de largo, pero es increíblemente importante -no todo el mundo usando MySQL es un administrador de bases de datos, y cuanta más gente lo adopte, más gente podrá vivir de él, tanto sus desarrolladores originales como proveedores externos.
Esta es mi propia lista de arreglos para los mensajes de EXPLAIN. Si ya eres un usuario experimentado de MySQL probablemente ya conozcas su sugnificado, pero eso no resuelve el problema para los principiantes. La razón por la que estoy escribiendo este post es para recoger opiniones sobre si os parecen importantes o no, y si mi manera de resolverlos parece razonable para poder enviarlas como “feature requests”.
Mensajes de EXPLAIN
Como instructor MySQL, el caso siguiente me ocurre mucho con nuevos estudiantes. Comienza con un comando como el siguiente:
mysql> EXPLAIN SELECT b, c FROM test\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test
type: index
possible_keys: NULL
key: b_c
key_len: 10
ref: NULL
rows: 4
Extra: Using index
1 row in set (0.00 sec)
Entonces, “Using index” significa que se está usando un índice, ¿verdad? No, en este caso type: index nos indica que se está usando un índice para escanear o acceder a las filas (porque no es un type: ALL– aunque podríamos obtener un full row scan e usar el índice para ordenar o agruparlas). El Extra: Using index indica que el índice se usa para devolver los datos, sin necesidad de leer la fila completa. A esto, por lo que yo sé, se le refiere comúnmente como Covering index. Y eso es exactamente lo que me gustaría ver:
mysql> EXPLAIN SELECT b, c FROM test\G -- salida editada
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test
type: index
possible_keys: NULL
key: b_c
key_len: 10
ref: NULL
rows: 4
Extra: Using covering index
1 row in set (0.00 sec)
o alternativamente:
Extra: Covering index
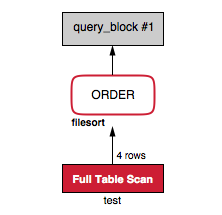
Otro malentendido común: Using filesort:
mysql> EXPLAIN SELECT * FROM test ORDER BY length(b)\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 4
Extra: Using filesort
1 row in set (0.00 sec)
A este nivel no me interesa si estoy usando filesort como algoritmo y -si no me equivoco- desde 5.6 también se puede usar una cola de prioridad como algoritmo de ordenamiento si el numero de elementos es pequeño. Además, el “file” de la palabra filesort puede llevar la confusión de que esto requiera una tabla temporal en disco. No tengo una alternativa perfecta (por favor, dadme ideas), pero algo como lo siguiente sería más claro:
mysql> EXPLAIN SELECT * FROM test ORDER BY length(b)\G -- salida editada
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 4
Extra: Additional sort phase
1 row in set (0.00 sec)
o alternativamente:
Extra: Not using index for order-by
Otro ejemplo sería:
mysql> EXPLAIN SELECT a FROM test WHERE b > 3 and c = 3\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test
type: range
possible_keys: b_c
key: b_c
key_len: 5
ref: NULL
rows: 1
Extra: Using index condition
1 row in set (0.00 sec)
Entiendo que quizá los desarrolladores no quisieron confundirnos con la técnica pushed condition de NDB, pero esta salida lleva al equívoco también. Literalmente significa que “la condición del índice se está usando”, en vez de que se está usando “ICP. ¿Qué os parece:
mysql> EXPLAIN SELECT a FROM test WHERE b > 3 and c = 3\G -- salida editada
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test
type: range
possible_keys: b_c
key: b_c
key_len: 5
ref: NULL
rows: 1
Extra: Using index condition pushdown
1 row in set (0.00 sec)
Hay muchas otras expresiones, pero esas son las que más me molestas en términos de confusión de estudiantes.
¿Estás de acuerdo conmigo? ¿Romperían estos cambios aplicaciones que parsean la salida de EXPLAIN? ¿Qué otras pequeñas cosas cambiarías en la salida de MySQL or sus mensajes de error? Me gustaría oír especialmente a los que están empezando con MySQL y a las personas que vengan de otras bases de datos, ya que cuanto más lo usamos, más nos acostumbramos a los MySQLismos.
Sin embargo, he visto mucha gente que asumía que porque el valor por defecto de default_tmp_storage_engine es “InnoDB”, todas las tablas temporales se crean en formato InnoDB. Esto no es cierto: primero, porque las tablas temporales implícitas se continúan creando en memoria usando el motor MEMORY (a veces denominado HEAP), mientras que MyISAM se usa para tablas en disco. Si no te fías para esto del manual de renferencia, aquí tienes una prueba rápida para comprobarlo:
mysql> SELECT version(); +------------+ | version() | +------------+ | 5.6.23-log | +------------+ 1 row in set (0.00 sec)
mysql> SHOW GLOBAL VARIABLES like 'default%'; +----------------------------+--------+ | Variable_name | Value | +----------------------------+--------+ | default_storage_engine | InnoDB | | default_tmp_storage_engine | InnoDB | | default_week_format | 0 | +----------------------------+--------+ 3 rows in set (0.00 sec)
mysql> SHOW GLOBAL VARIABLES like 'tmpdir'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | tmpdir | /tmp | +---------------+-------+ 1 row in set (0.00 sec)
mysql> CREATE TABLE test (id serial, a text); Query OK, 0 rows affected (0.10 sec)
mysql> insert into test (a) values ('a'); Query OK, 1 row affected (0.06 sec)
mysql> insert into test (a) values ('aa'); Query OK, 1 row affected (0.00 sec)
mysql> insert into test (a) values ('aaa'); Query OK, 1 row affected (0.00 sec)
mysql> SELECT *, sleep(10) FROM test ORDER BY rand(); ...
[ec2-user@jynus_com tmp]$ ls -la total 24 drwxrwxrwt 5 root root 4096 Feb 24 11:55 . dr-xr-xr-x 23 root root 4096 Jan 28 14:09 .. drwxrwxrwt 2 root root 4096 Jan 28 14:09 .ICE-unix -rw-rw---- 1 mysql mysql 0 Feb 24 11:55 #sql_7bbd_0.MYD -rw-rw---- 1 mysql mysql 1024 Feb 24 11:55 #sql_7bbd_0.MYI drwx------ 2 ec2-user ec2-user 4096 Feb 24 11:41 ssh-5ZGoXWFwtQ drwx------ 2 ec2-user ec2-user 4096 Feb 24 11:43 ssh-w9IkW0SvYo
... +----+------+-----------+ | id | a | sleep(10) | +----+------+-----------+ | 1 | a | 0 | | 2 | aa | 0 | | 3 | aaa | 0 | +----+------+-----------+ 3 rows in set (30.00 sec)
La única cosa que he hecho aquí arriba es forzar la creación de la tabla temporal en disco añadiendo un campo de tipo TEXT (incompatible con el motor MEMORY, por lo que se fuerza su creación en disco) y usar sleep para tener el suficiente tiempo como para comprobar el sistema de archivos. En la salida de ls podéis observar los .MYD y .MYI particulares del motor MyISAM. El último paso sería innecesario si simplemente utilizaramos PERFORMANCE_SCHEMA para comprobar los waits/io.
Una segunda, y más obvia razón por la que pensar que todas las tablas temporales se crean en formato InnoDB es incorrecto, es porque las tablas temporales explícitas pueden seguir creándose en un motor distinto con la palabra clave ENGINE:
mysql> CREATE TEMPORARY TABLE test (i serial) ENGINE=MyISAM; Query OK, 0 rows affected (0.00 sec)
[ec2-user@jynus_com tmp]$ ls -la total 36 drwxrwxrwt 5 root root 4096 Feb 24 12:16 . dr-xr-xr-x 23 root root 4096 Jan 28 14:09 .. drwxrwxrwt 2 root root 4096 Jan 28 14:09 .ICE-unix -rw-rw---- 1 mysql mysql 8554 Feb 24 12:12 #sql7bbd_36a3_0.frm -rw-rw---- 1 mysql mysql 0 Feb 24 12:12 #sql7bbd_36a3_0.MYD -rw-rw---- 1 mysql mysql 1024 Feb 24 12:12 #sql7bbd_36a3_0.MYI drwx------ 2 ec2-user ec2-user 4096 Feb 24 11:41 ssh-5ZGoXWFwtQ drwx------ 2 ec2-user ec2-user 4096 Feb 24 11:43 ssh-w9IkW0SvYo
[ec2-user@jynus_com tmp]$ ls -la total 20 drwxrwxrwt 5 root root 4096 Feb 24 12:17 . dr-xr-xr-x 23 root root 4096 Jan 28 14:09 .. drwxrwxrwt 2 root root 4096 Jan 28 14:09 .ICE-unix drwx------ 2 ec2-user ec2-user 4096 Feb 24 11:41 ssh-5ZGoXWFwtQ drwx------ 2 ec2-user ec2-user 4096 Feb 24 11:43 ssh-w9IkW0SvYo
¿Cambiará esto en el futuro? 5.7.5 continua teniendo el mismo comportamiento que 5.6. Sin embargo, tal y como indicó Stewart hace un tiempo, las optimizaciones de rendimiento de 5.7 hacen que ciertos usos de MEMORY y MyISAM sean ahora obsoletos, por lo que no me sorprendería que esta dependencia -junto con la de las tablas de permisos MyISAM- desapareciera en un futuro.
Actualización:Morgan me ha contado por email que en la versión 5.7.6 (que todavía no se ha publicado en el momento de escribir estas líneas) cambiará finalmente el comportamiento por defecto para pasar a utilizar sólo InnoDB para las tables temporales implícitas tal y como se puede leer en las notas de actualización:
InnoDB: The default setting for the internal_tmp_disk_storage_engine option, which defines the storage engine the server uses for on-disk internal temporary tables (see How MySQL Uses Internal Temporary Tables), is now INNODB. With this change, the Optimizer uses the InnoDB storage engine instead of MyISAM for internal temporary tables.
que se puede traducir más o menos como:
InnoDB: el valor por defecto de la opción internal_tmp_disk_storage_engine option, que define el motor por defecto que el servidor usa para las tablas temporales internas en disco (véase Cómo utiliza MySQL tablas temporales), tiene ahora el valor INNODB. Con este cambio, el optimizador usa ahora el motor de almacenamiento InnoDB en vez de MyISAM para las tablas temporales internas.
internal_tmp_disk_storage_engine se introdujo en 5.7.5, pero su valor por defecto era MYISAM.
Esto permitirá una ventaja con el rendimiento de InnoDB en memoria para campos de tamaño variable, por lo que estoy 100% a favor. ¡Gracias Morgan por la información extra!
El próximo sábado 8 de noviembre a las 19:30 estaré hablando sobre MySQL Fabric en la PyConES 2014 (la versión española de la PyCon), la reunión anual de programadores y entusiastas de Python en España. Aunque no me auto-denomino como programador, una gran parte de mi tiempo cono consultor de MySQL require implementar procedimientos automáticos (backups, comprobaciones de salud, gestión de AWS, …) y para ello utilizo principalmente una combinación de Python y Bash.
En mi charla, que he titulado “MySQL Fabric, a High Availability solution for Connector/Python” explicaré cómo montar y configurar un conjunto de servidores MySQL y aplicaciones clientes Python usando Connector/Python con el objetivo de proporcionar estabilidad en el servicio y rendimiento extra tanto para lecturas como para escrituras (gracias a sus capacidades de proporcionar sharding de manera semi-automática) para tu aplicación. El framework en sí mismo (Fabric, parte de las MySQL Utilities) es software libre y está siendo muy activamente desarrollado (también programado en Python, por supuesto!). Si en cualquier punto de tu carrera has sufrido de bajo rendimiento de tu base de datos, o pérdida de servicio, tienes que pasarte por mi charla! También lo compararé con otros productos relativamente similares, indicando los pros y contras de cada uno. La sesión se impartirá en inglés.
El lunes de la próxima semana, 3 de noviembre, impartiré un tutorial de la mayor conferencia europea de MySQL, la Percona Live London 2014. El tema es una continuación natural de la que impartí el año pasado en el mismo lugar, “Optimización de consultas con MySQL 5.6: trucos nuevos y viejos“. Este año me centraré en los últimos cambios en el optimizador que podemos encontrar no sólo en los ya publicados 5.6 y MariaDB 10, pero también alguna de las características de los todavía en desarrollo MySQL 5.7 y MariaDB 10.1. Algunos de los temas de este taller, que he titulado “Optimización de consultas con MySQL 5.7 y MariaDB 10: más trucos que nunca“, incluyen: el nuevo optimizador de 5.7 basado en costes, columnas virtuales, api para plugins de reescritura de consultas, nuevos métodos de JOIN, optimización de subconsultas, cambios en los modos sql, búsqueda de cadenas full text search y mejoras en GIS. Todo ello con ejemplos fáciles de seguir y prácticas en ordenador.
Aquí tenéis la agenda completamente detallada (se impartirá en inglés):
Introduction
Break (VM installation)
General Optimizer Improvements
Computed/Virtual Columns
Query Rewrite Plugins
SQL Mode Changes
Join Optimization
Subquery Optimization
Fulltext search
GIS Improvements
Break
Query Profiling
Results and Conclusions
Q&A
Actualización: Aquí tenéis las transparencias completas:
Aunque proporcionaré llaves USB con esos mismos archivos, y podrás seguir la explicación tan sólo viendo mi pantalla ya que mostraré todo por mí mismo, sin embargo podrás sacar mucho más partido al tutorial si te tomas 5 minutos para preparar tu sistema por adelantado.
Regalaré varios pendrives entre aquellos que se tomen el tiempo para preparar sus sistemas con anterioridad y asistan a mi tutorial, como un gesto de agradecimiento para hacer la sesión más ágil. Mencióname en Twitter diciendo algo como “Ya he preparado todo para el tutorial de @dbahire_es http://dbahire.com/pluk14 #perconalive”, de manera que pueda reservarte uno!
Os veo el próximo martes a las 9:00 hora de Londres en el “Orchard 2”.
Como mencioné en mi anterior entrada, donde comparaba las opciones de configuración por defecto de 5.6 y 5.7, he estado haciendo algunos tests para un tipo particular de carga en varias versiones de MySQL. Lo que he estado comprobando es las diferentes maneras de cargar un archivo CSV (el mismo fichero que usé para comprobar las herramientas de compresión) en MySQL. Aquellos administradores de bases de datos y programadores MySQL con experiencia probablemente ya conozcáis la respuesta, así que podéis saltar a los resultados de 5.7 respecto de 5.6. Sin embargo, la primera parte de este post está dedicado a los desarrolladores/aquellos que dan sus primeros pasos con MySQL que desean saber la respesta a la pregunta del título, paso a paso. Debo decir que yo también he aprendido algo, ya que sobrestimé e infravaloré algunos efectos de ciertas opciones de configuración para este tipo de carga.
Aviso: no pretendo realizar benchmarks formales, la mayoría de los resultados obtenidos aquí se han creado ejecutándose un par de veces, y muchos de ellos con la configuración por defecto. Esto ha sido por diseño, ya que intento mostrar alguna de las “malas prácticas” para la gente que acaba de empezar a trabajar con MySQL, y lo que deberían evitar hacer. Tan sólo la comparativa entre 5.6 y 5.7 me ha llamado la antención. Aviso adicional: No me llamo a mí mismo programador, y mucho menos un programador de Python, así que me disculpo por adelantado por mi código- después de todo, esto va de MySQL. El enlace de descarga de los scripts está al final del post.
Las reglas
Empiezo con un archivo CSV (recordad que realmente es un archivo de valores separado por comas, TSV) que tiene 3.700.635.579 bytes de tamaño, y 46.741.126 filas y tiene la siguiente pinta:
El tiempo de importación termina en el momento que la tabla es crash safe (resistente a fallos) (aunque quede E/S pendiente). Eso quiere decir que para InnoDB, el último COMMIT realizado tiene que haberse hecho de manera satisfactoria y flush_log_at_trx_commit debe valer 1, de manera que aunque queden operaciones de escritura por hacerse, es completamente consistente con disco. Para MyISAM, eso quiere decir que fuerzo la ejecución de un FLUSH TABLES antes de terminar el test. Estos, por supuesto, no son equivalentes, pero al menos es una manera de asegurarse de que todo está más o menos sincronizado con disco. Ésta es la parte final de todos mis scripts:
Para el hardware y sistema operativo, comprobad los detalles de máquina de este post antiguo– usé el mismo entorno que el mencionado aquí, con la excepción de usar CentOS7 en vez de 6.5.
Empezando con un método muy ingenuo
Digamos que soy un desarrollador al que le han asignado cargar de manera regular un archivo en MySQL, ¿cómo lo haría? Probablemente estaría tentado de usar una biblioteca de parseo de CSV, el conector de MySQL, y los uniría a ambos juntos en un bucle. ¿Eso funcionaría, no? La parte principal del código sería algo como esto (load_data_01.py):
# import
insert_node = "INSERT INTO nodes (id, lat, lon, version, timestamp, changeset, uid, user) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)"
with open(CSV_FILE, 'rb') as csv_file:
csv_reader = csv.reader(csv_file, delimiter='\t')
for node in csv_reader:
cursor.execute(insert_node, node)
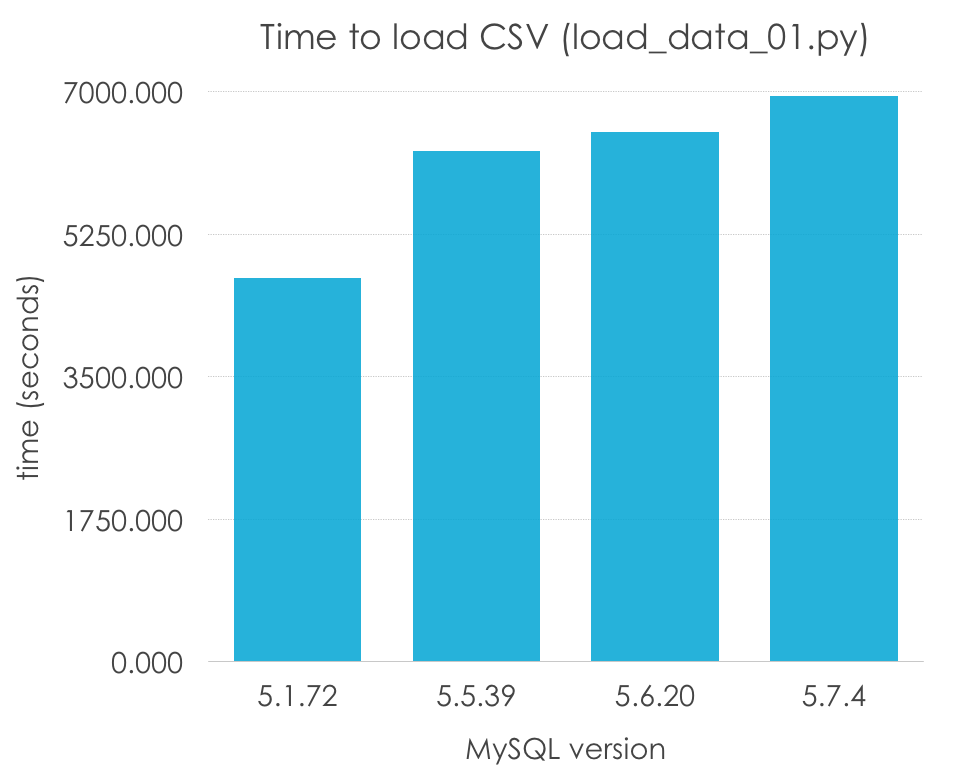
Como estoy interpretando el papel de un desarrollador sin experiencia, también usaría la configuración por defecto. Veamos qué resultados obtenemos (de nuevo, esta es la razón por la cual llamo a esto “pruebas”, y no benchmarks). Menos es mejor:
MySQL Version
5.1.72
5.5.39
5.6.20
5.7.4
Load time (seconds)
4708.594
6274.304
6499.033
6939.722
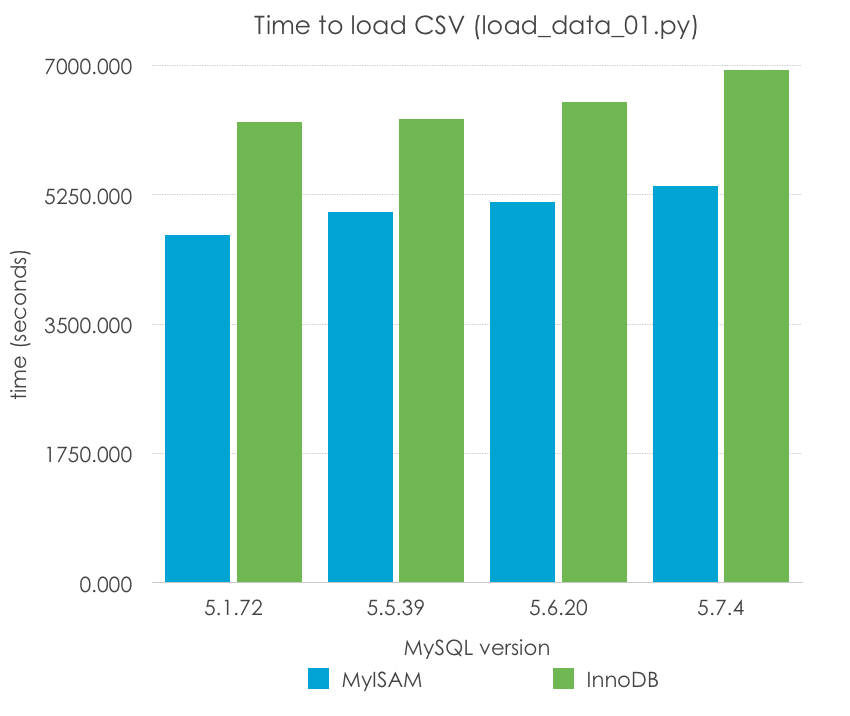
Guau, ¿5.1 es un 50% más rápido que el resto de versiones? Incorrecto, recordad que 5.5 fue la primera versión en introducir InnoDB como el motor por defecto, e InnoDB tiene una sobrecarga debido a las transacciones, y normalmente no tiene una muy buena configuración por defecto (al contrario que MyISAM, que estan simple que las opciones por defecto pueden funcionar en muchos casos). Normalicemos los resultados por motor de almacenamiento:
MySQL Version
5.1.72
5.5.39
5.6.20
5.7.4
MyISAM
4708.594
5010.655
5149.791
5365.005
InnoDB
6238.503
6274.304
6499.033
6939.722
Esto ya parece más razonable, ¿no? Sin embargo, en este caso, parece haber una ligero empeoramiento en el rendimiento de un sólo hilo a la vez que las versiones van progresando, especialemnte en MySQL 5.7. Por supuesto, es pronto para sacar conclusiones, porque este método de carga de un archivo CSV, fila a fila, es uno de los más lentos, y además estamos usando unas opciones de configuración muy pobres (las que vienen por defecto) -las cuales varían de versión a versión- y que no deberían usarse para llegar a ninguna conclusión.
Lo que podemos decir es que MyISAM parece funcionar mejor para este escenario muy específico por las razones que comentaba antes, pero aún así tardaríamos de 1 a 2 horas en cargar un archivo tan sencillo.
Otro método incluso más ingenuo
La siguiente pregunta no es: ¿podemos hacerlo mejor? sino ¿podemos hacerlo incluso más lento? Un texto en particular me llamó la atención mientras miraba la documentación del conector de MySQL:
Since by default Connector/Python does not autocommit, it is important to call this method after every transaction that modifies data for tables that use transactional storage engines.
que es algo así como:
Debido a que por defecto Connector/Python no realiza autocommit, es importante llamar a este método después de cualquier transacción que modifique datos en tablas de motores transaccionales.
Pensé- ¡ah!, entonces podemos reducir el tiempo de importación realizando commit para cada fila de la base de datos, una a una, ¿no? Después de todo, estamos insertando en la tabla en una única transacción enorme. ¡Seguro que crear un enorme número de transacciones será mejor! 🙂 Este es el código ligeramente modificado (load_data_02.py):
insert_node = "INSERT INTO nodes (id, lat, lon, version, timestamp, changeset, uid, user) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)"
with open('/tmp/nodes.csv', 'rb') as csv_file:
csv_reader = csv.reader(csv_file, delimiter='\t')
for node in csv_reader:
cursor.execute(insert_node, node)
db.commit()
Y en este caso no tengo ni siquiera un bonito gráfico que enseñaros, porque después de 2 horas, 19 minutos y 39.405 segundos, cancelé la importación porque sólo se habían insertado 111533 nodos en MySQL 5.1.72 con InnoDB con la configuración por defecto (innodb_flush_log_at_trx_commit = 1). Obviamente, millones de fsyincs no harán que la carga sea más rápida, considerad esto como una lección aprendida.
Haciendo progresos: multi-inserts
El siguiente paso que quería probar es cómo de efectivo es agrupar consultas en inserciones múltiples. Este método lo usa mysqldump, y supuesta mente minimiza la carga extra de SQL por tener que gestionar cada consulta por separado (parseo, comprobación de permisos, plan de la consulta, etc.). Éste es el código principal (load_data_03.py):
concurrent_insertions = 100
[...]
with open(CSV_FILE, 'rb') as csv_file:
csv_reader = csv.reader(csv_file, delimiter='\t')
i = 0
node_list = []
for node in csv_reader:
i += 1
node_list += node
if (i == concurrent_insertions):
cursor.execute(insert_node, node_list)
i = 0
node_list = []
csv_file.close()
# insert the reminder nodes
if i > 0:
insert_node = "INSERT INTO nodes (id, lat, lon, version, timestamp, changeset, uid, user) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)"
for j in xrange(i - 1):
insert_node += ', (%s, %s, %s, %s, %s, %s, %s, %s)'
cursor.execute(insert_node, node_list)
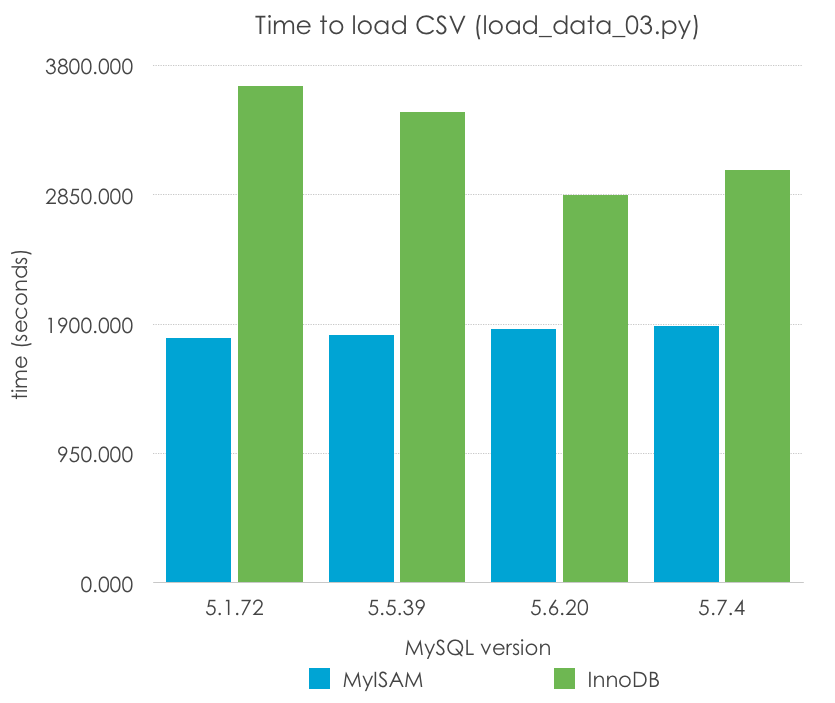
Lo probamos con, por ejemplo, 100 filas insertadas en cada consulta. ¿Cuáles son los resultados? Menos es mejor:
MySQL Version
5.1.72
5.5.39
5.6.20
5.7.4
MyISAM
1794.693
1822.081
1861.341
1888.283
InnoDB
3645.454
3455.800
2849.299
3032.496
Con este método observamos una mejora en el tiempo de importación de 262-284% respecto del tiempo original para MyISAM y de 171-229% respecto del tiempo original de InnoDB. Recordad que este método no escalará indefinidamente, ya que encontraremos un límite en el tamaño de paquete si intentamos insertar demasiadas filas a la vez. Sin embargo, se trata de una clara ventaja sobre el insertado fila a fila.
Los tiempos para MyISAM son esencialmente los mismos entre versiones, mientras que InnoDB muestra una mejora a lo largo del tiempo (que podrían deberse a los cambios en código y la optimización, pero también a la configuración por defecto del tamaño del log de transacciones), excepto de nuevo entre 5.6 y 5.7.
El método correcto para importar datos: Load Data
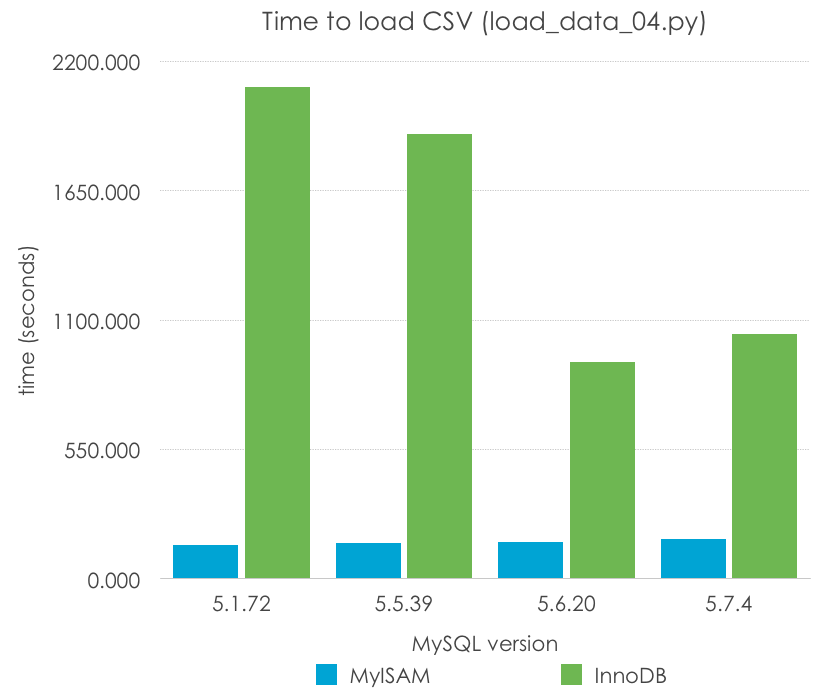
Si se tiene un mínimo de experiencia con MySQL, conoceréis la existencia de una palabra clave especializada para importaciones, y ésta es LOAD DATA. Veamos como quedaría el código usando esta opción (load_data_04.py):
# data import
load_data = "LOAD DATA INFILE '" + CSV_FILE + "' INTO TABLE nodes"
cursor.execute(load_data)
¿Simple, verdad? Con esto estamos minimizando la sobrecarga de SQL, y ejecutando el bucle en código C compilado de MySQL. Echemos un vistazo a los resultados (menos es mejor):
MySQL Version
5.1.72
5.5.39
5.6.20
5.7.4
MyISAM
141.414
149.612
155.181
166.836
InnoDB
2091.617
1890.972
920.615
1041.702
En este caso, MyISAM tiene una mejora dramática –LOAD DATA convierte la importación en 12 veces más rápida. InnoDB, de nuevo todavía con los parámetros por defecto mejora en 3 veces, y más significativamente en las versiones más recientes (5.6, 5.7) que en las anteriores (5.1, 5.5). Mi predicción es que esto tiene mucho más que ver con la diferente configuración de los archivos de log que con cambios en el código.
Intentado mejorar Load Data para MyISAM
¿Podemos mejorar los tiempos de carga para MyISAM? Hay dos cosas que podemos hacer -aumentar el tamaño de key_cache_size y deshabilitar Performance Schema para 5.6 y 5.7. Establecí el tamaño de la caché de índices (key_cache_size) en 600M (intentado que cupiera la clave primaria en memoria) y cambié performance_schema = 0, probando las 3 combinaciones restantes. Menos es mejor:
MySQL Version
5.1.72
5.5.39
5.6.20
5.7.4
default
141.414
149.612
155.181
166.836
key_buffer_size=600M
136.649
170.622
182.698
191.228
key_buffer_size=600M, P_S = OFF
133.967
170.677
177.724
186.171
P_S = OFF
142.592
145.679
150.684
159.702
Hay varias cosas que destacar aquí:
P_S=ON and P_S=OFF no debería tener un efecto en MySQL 5.1 y 5.5, pero se muestran resultados diferentes debido a errores de medida. De ahí podemos entender que sólo 2 cifras son realmente significativas.
key_buffer_cache, en general, no mejora el rendimiento, de hecho se podría decir que estadísticamente la empeora. Esto es razonable porque, después de todo, estoy escribiendo a la caché de archivos, y una caché de claves mayor puede requerir una reserva o copia de memoria más costosa. Esto debería investigarse más a fondo para llegar a una conclusión.
Performance_schema podría estar empeorando el rendimiento de esta carga, pero no estoy seguro estadísticamente hablando.
MyISAM (o quizás el servidor MySQL) parece haber empeorado su rendimiento para este tipo de carga (carga por lotes con un sólo hilo).
Hay más cosas que me gustaría probar con MyISAM, como ver el impacto de los diferentes formatos de fila (fixed) pero me gustaría continuar con los otros motores.
Intentado mejorar Load Data en InnoDB
InnoDB es un motor mucho más interesante, ya que es ACIDo por defecto, y más complejo. ¿Podemos hacerlo tan rápido como MyISAM para una importación?
La primera cosa que quiero cambiar son los valores por defecto de innodb_log_file_size y innodb_buffer_pool_size. El log es diferente antes y después de 5.6, y no es adecuado para una gran carga de escritura. Lo cambié para un primer test a 2G, que es el mayor tamaño que 5.1 y 5.5 pueden usar (lo puse a 2.147.483.136 ya que tiene que se menor de 2G), lo cual quiere decir que tenemos un tamaño total de los logs de 4G. También cambié el buffer pool a una tamaño más conveniente, 8GB, suficiente para albergar el tamaño completo del conjunto de datos. Recordad que una de las razones por las cuales InnoDB es tan lento a la hora de realizar importaciones es porque escribe las nuevas páginas (al menos) dos veces a disco -en el log, y en el espacio de tablas. Sin embargo, con estos parámetros, la segunda escritura debería realizarse en su mayoría a través del buffer de memoria. Estos son los nuevos resultados (menos es mejor):
MySQL Version
5.1.72
5.5.39
5.6.20
5.7.4
default
1923.751
1797.220
850.636
1008.349
log_file_size=2G, buffer_pool=8G
1044.923
1012.488
743.818
850.868
Ahora esto es un test que parece más razonable. Podemos comentar que:
La mayoría de las mejoras que teníamos antes en 5.6 y 5.7 respecto a 5.1 y 5.5 se debían al tamaño de log 10 veces más grande.
Aún así, 5.6 y 5.7 son más rápidos que 5.1 y 5.5 (algo razonable, ya que 5.6 ha visto unos cambios en InnoDB impresionantes, tanto en código como en configuración)
InnoDB continúa siendo al menos 5 veces más lento que MyISAM
¡Y 5.7 continúa siendo más lento que 5.6! Estamos teniendo una regresión consistente de un 13-18% en 5.7 (y me estoy empezando, ahora sí, a preocupar)
Comenté antes que el mayor overhead de InnoDB es escribir los datos 2 veces (al log y a las tablas). Esto es en realidad incorrecto, ya que podría tener que escribirlos 3 veces (al área de doble escritura) e incluso 4, en el log binario. El log binario no está activo por defecto, pero el double write sí, ya que permite protegernos de la corrupción. Aunque nunca recomendamos deshabilitar esta estructura en producción, la verdad es que en una importación nos da igual si los datos terminan corruptos (ya que podríamos borrarlos y volver a reimportarlos). También hay opciones en algunos sistemas de archivos para evitar tener que activarlo.
Otras características que están en InnoDB por seguridad, no por rendimiento, son los checksums de InnoDB- éstos incluso se convierten en el cuello de botella en sistemas de almacenamiento utrarrápidos como tarjetas flash PCI. En estos casos, ¡la CPU es demasiado lenta para calcularlos! Sospecho que esto no será un problema en este caso porque las versiones más modernas de MySQL (5.6 y 5.7) tienen la opción de cambiarlo por la función acelerada por hardare CRC32 y, mayormente, porque estoy usando discos magnéticos, que son el verdadero cuello de botella aquí. Pero no nos fiemos de lo que hemos aprendido y pongámoslo a prueba.
La otra cosa que podemos comprobar es la sobrecarga de performance_schema. He encontrado casos en los que por el tipo de operaciones produce tiene un efecto negativo bastante notable, mientras que casi ninguno en otros. Probemos también a activarlo y deshabilitarlo.
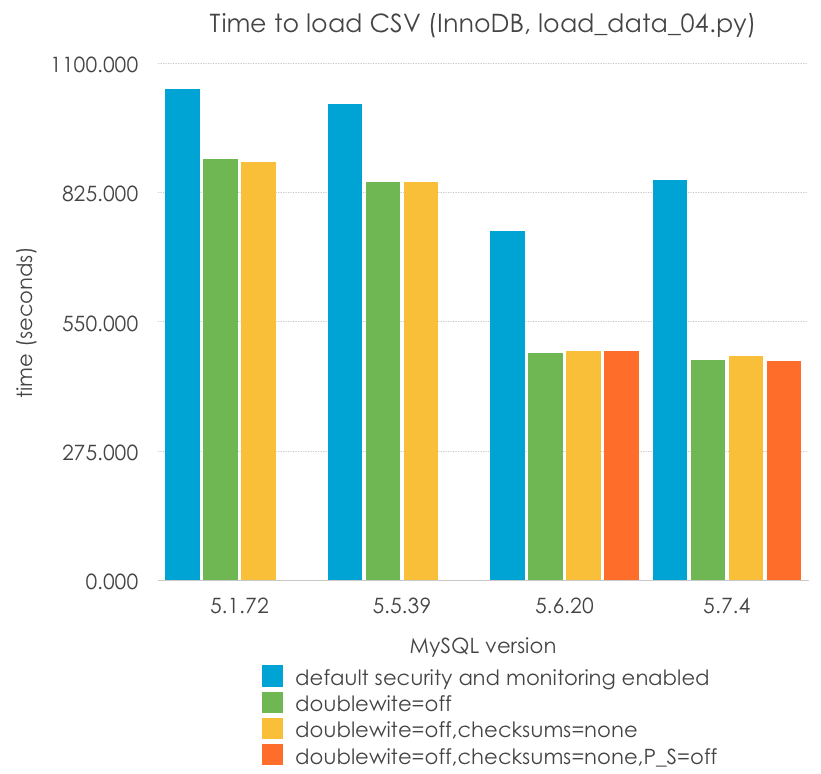
Estos son los resultados (menos es mejor):
MySQL Version
5.1.72
5.5.39
5.6.20
5.7.4
default security and monitoring enabled
1044.923
1012.488
743.818
850.868
doublewrite=off
896.423
848.110
483.542
468.943
doublewrite=off,checksums=none
889.827
846.552
488.311
476.916
doublewrite=off,checksums=none,P_S=off
488.273
467.716
Hay varias cosas que comentar aquí, alguna de las cuales ni siquiera soy capaz de proporcionar una explicación:
El doublewrite no reduce el rendimiento a la mitad, pero impacta de manera significativa en el rendimiento (entre un 15% y un 30%)
Sin la escritura doble, la mayoría de la regresión de 5.7 desaparece (¿por qué?)
El doublewrite es más significativo en 5.6 y 5.7 que en versiones previas de MySQL. Me atrevería a decir que la mayoría de otros cuellos de botella han sido eliminados (¿o quizá sea algo como las particiones del buffer pool estando activas por defecto?)
Los checksums de innodb no producen absolutamente ninguna diferencia para este tipo de carga y hardware en particular.
De nuevo, no puedo dar significado estadístico a una pérdida de rendimiento del performance schema. Sin embargo, he obtenido resultados muy variables en los tests, con resultados como un 10% de latencia extra en los valores centrales respecto aquellas con él deshabilitado, pero no estoy 100% seguro de esto.
En resument, con unos pocos cambios aquí y allí, podemos obtener resultados que tan sólo son el doble de lentos que MyISAM, en vez de 5 veces o 12 veces.
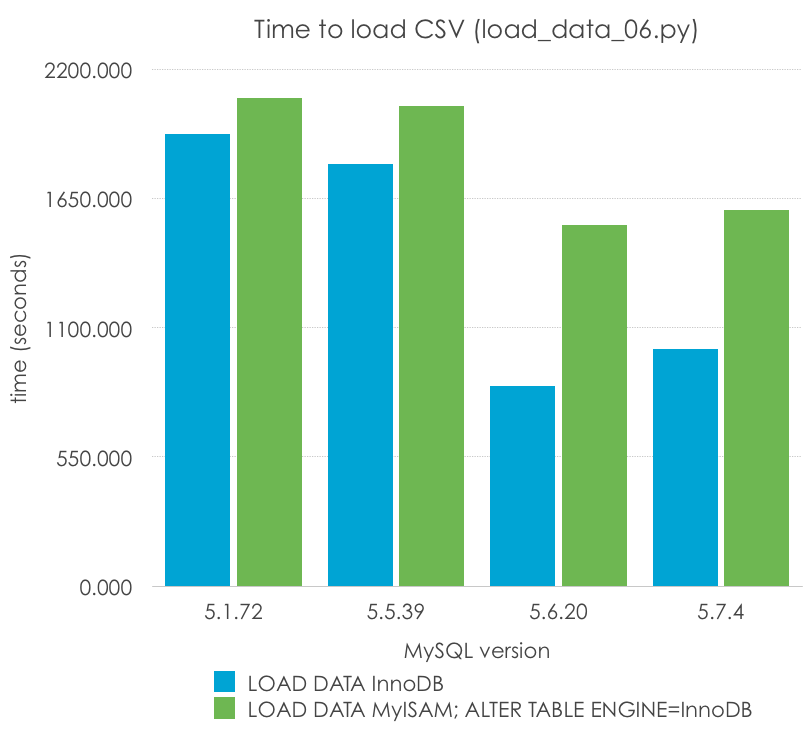
Importar en MyISAM, convertir a InnoDB
He visto a veces a algunas personas en los foros recomendar la importación de una tabla en formato MyISAM, y después convertirla a InnoDB. Veamos si podemos pillar o confirmar este mito con el siguiente código (load_data_06.py):
load_data = "LOAD DATA INFILE '/tmp/nodes.csv' INTO TABLE nodes"
alter_table = "ALTER TABLE nodes ENGINE=InnoDB"
cursor.execute(load_data)
cursor.execute(alter_table)
Esta es la comparación (menos es mejor):
MySQL Version
5.1.72
5.5.39
5.6.20
5.7.4
LOAD DATA InnoDB
1923.751
1797.220
850.636
1008.349
LOAD DATA MyISAM; ALTER TABLE ENGINE=InnoDB
2075.445
2041.893
1537.775
1600.467
Puedo ver cómo esto podría ser casi cierto en 5.1, pero es claramente falso en todas las versiones soportadas de MySQL. Sin embargo, tengo que remarcar que es más rápido que importar la tabla dos veces, una para MyISAM y otra para InnoDB.
Dejaré como deberes para el lector comprobarlo para otros motores, como MEMORY o CSV [Pista: Quizá podemos importar a éste último motor de una manera diferente].
Carga de manera paralela
MyISAM escribe a las tablas usando un bloqueo a nivel de tabla (aunque en algunos casos es posible realizar inserts concurrentes), pero InnoDB sólo requiere un bloqueo a nivel de fila en muchos casos. ¿Podríamos acelerar el proceso realizando una importación en paralelo? Esto es lo que quise probar con mi último test. No confío en mis habilidades de programación (o más bien no tengo mucho tiempo) para realizar el movimiento de cursor de archivo y el particionamiento de manera eficiente, así que comenzaré con un .csv ya dividido en 8 trozos. No debería llevar mucho tiempo, pero las herramientas limitadas de la librería de threads por defecto, así como mi falta de tiempo me hicieron optar por este plan. Tan sólo debemos ser conscientes de que no comenzamos con el mismo escenario exacto en este caso. Este es el código (load_data_08.py):
NUM_THREADS = 4
def load_data(port, csv_file):
db = mysql.connector.connect(host="localhost", port=port, user="msandbox", passwd="msandbox", database="test")
cursor = db.cursor()
load_data_sql = "LOAD DATA INFILE '" + csv_file + "' INTO TABLE nodes"
cursor.execute(load_data_sql)
db.commit()
thread_list = []
for i in range(1, NUM_THREADS + 1):
t = threading.Thread(target=load_data, args=(port, '/tmp/nodes.csv' + `i`))
thread_list.append(t)
for thread in thread_list:
thread.start()
for thread in thread_list:
thread.join()
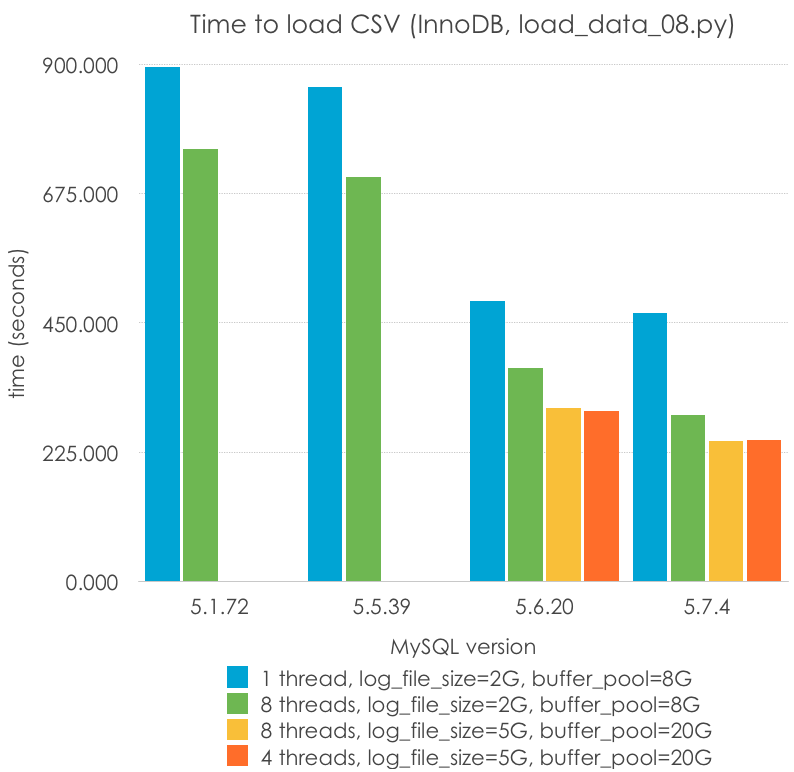
Y estos son los resultados, con diferentes parámetros (menos es mejor):
MySQL Version
5.1.72
5.5.39
5.6.20
5.7.4
1 thread, log_file_size=2G, buffer_pool=8G
894.367
859.965
488.273
467.716
8 threads, log_file_size=2G, buffer_pool=8G
752.233
704.444
370.598
290.343
8 threads, log_file_size=5G, buffer_pool=20G
301.693
243.544
4 threads, log_file_size=5G, buffer_pool=20G
295.884
245.569
En este método podemos ver que:
Hay pocos cambios de rendimiento entre realizar la carga paralela con 4 u 8 threads. Esta es una máquina con 4 cores (8 HT)
La paralelización ayuda, aunque no escala (4-8 hilos proporcionan alrededor de un 33% de velocidad)
Éste es el caso en le que 5.6 y especialmente 5.7 destacan
Un log de transacciones y un buffer pool mayor (de más de 4G, sólo disponible en 5.6+) siguen siendo útiles para reducir la carga
La carga paralela con 5.7 es la manera más rápida en la que puedo cargar este archivo usando InnoDB: 243 segundos. Es 1.8x veces la manera más rápida en la que puedo cargar una tabla en MyISAM (5.1, monohilo): 134 seconds. ¡Esto son casi 200K filas/s!
Resumen y preguntas abiertas
La manera más rápida en la que puedes importar una tabla en MySQL sin usar archivos binarios es usando la sintaxis LOAD DATA. Usa la paralelización en InnoDB para mejorar los resultados, y recuerda ajustar parámetros básicos como el tamaño de archivo de transacciones y el buffer pool. Una programación y imporación hecha con el debido cuidado pueden convertir un problema de más de 2 horas en un proceso de apenas 2 minutos. Es posible deshabilitar temporalmente algunas características de seguridad para obtener rendimiento extra.
Parece haber una importante regresión en 5.7 para esta carga en particular de una importación monohlo tanto para MyISAM como para InnoDB, con unos resultados hasta un 15% peores en rendimiento que 5.6. Todavía no sé porqué.
En el aspecto positivo, parece haber un aumento (de hasta el 20%) en relación con 5.6 en una carga paralela de escrituras.
Es posible que haya un impacto en el rendimiento de Performance schema para este tipo de operación, pero soy incapaz de medirlo de manera fiable (es más cercando a 0 que mi error de medida). Esto es algo positivo.
Estaría agradecido si me pudierais indicar cualquier error en alguna de mis suposiciones.
Recordad que esto no son benchmarks “formales”, y que ya no dispongo de acceso a la máquina donde los generé. Todavía tengo pendiente el analizar si existe el mismo problema en 5.7.5. Hay otras personas apuntando a regresiones bajo limitada concurrencia, como Mark Callaghan, quizá estén relacionados? Como de costumbre, podéis dejarme un comentario aquí o mandarme una respuesta mediante Twitter.
Por supuesto, esto sólo es un título para llamar la atención. Por lo que yo sé no todas las tablas de sistema se pueden convertir a InnoDB todavía (por ejemplo, las tablas de privilegios), lo cual convierte la cabecera en técnicamente falsa. MyISAM es un motor muy simple, y eso tiene algunas ventajas inherentes (no hay carga extra debido a las transacciones, más fácil de “editar” manualmente, normalmente ocupa menos espacio en disco), pero también algunas desventajas bastante importantes: no es seguro en el caso de un cuelgue general, no hay claves foráneas, sólo bloqueos a nivel de tabla, problemas de consistencia, bugs en tablas muy grandes,… La versión 5.7.5 “Milestone 15”, presentada hoy en el Oracle Open World tiene una impresionante lista de cambios, la cual necesitaré un tiempo para digerir, como una replicación multi-master (¿syncrona?) en fase de desarrollo o un completamente cambiado optimizador de consultas. Pero el cambio en particular que quiero destacar hoy es que la última de las “3 grandes” razones para usar MyISAM ha desaparecido finalmente. Para mí (y mis clientes) esas razones eran:
Espacio de tablas transportable
En MyISAM, mover una tabla en formato binario de una servidor a otro era (y sigue siendo) muy fácil- tirar el servidor y copiar los archivos .MYI, .MYD y .frm. Incluso se podría hacer en caliente con las debidas precauciones: se podía copiar los ficheros de tabla si se ejecutaba antes el infame “FLUSH TABLES WITH READ LOCK;” y usar eso como una backup.
Antes de 5.6, MySQL requería una parche para que esto funcionara de manera segura. Ahora, tablas individuales pueden exportarse e importarse sin problemas en formato binario, incluso entre diferentes servidores.
Índices Fulltext
La búsqueda de cadenas de texto fulltext nunca ha sido el punto fuerte de MySQL (y he ahí la razón por la que mucha gente lo combina con Sphinx o Apache Lucene/Solr). Pero muchos usuarios no requieren un clon de Google Search, sólo una manera rápida de buscar en una web pequeñita, o en una columna de descripción, y como sabemos, los índices BTREE no son útiles en expresiones como like '%palabra_buscada%'.
Los índices y búsquedas FULLTEXThan estado disponibles desde MySQL 3.23.23, pero sólo para MyISAM. Yo no sé vosotros, pero yo he encontrado un relativo alto número de clientes cuya única razón para seguir usando MyISAM era “necesitamos búsquedas fulltext”. A partir de MySQL 5.6.4, el soporte a fulltext fue añadido a InnoDB, eliminando la necesidad de decidir entre la transaccionalidad y la búsqueda rápida de cadenas. A pesar de que los comienzos no fueran precisamente geniales, (especialmente si los comparamos con otras soluciones externas y más complejas) y que fue publicado con algunos bugs importantes que afectaban a la estabilidad; los últimos cambios en el soporte de fulltext en innodb indican que se sigue trabajando para mejorar su rendimiento.
Soporte a GIS
Éste es cambio que los ingenieros de MySQL añadieron en MySQL 5.7.5. Por supuesto, los tipos de datos GIS estaban disponibles desde MySQL 4.1 para MyISAM, y en 5.0.16 para la mayoría de otros motores de primeras partes, incluyendo InnoDB. Sin embargo, esos tipos no son útiles si no se pueden utilizar de manera rápida en operaciones geográficas comunes como encontrar si dos polígonos se solapan o encontrar todos los puntos que están cerca de otro dado. La mayoría de estas operaciones requieren el indexado en 2 dimensiones, algo que no funciona muy bien con índices BTREE estándares. Para ello, necesitamos R-Trees o Quadtrees, estructuras que nos permitirán el indexado eficiente de valores multidimensionales. Hasta ahora, esos índices de tipo SPATIAL, como se les llama en sintaxis MySQL, sólo estaban disponibles en MyISAM- de forma que de nuevo teníamos que decidir entre transacciones y claves foráneas o operaciones GIS eficientes. Esta es una de las razones por las cuales proyectos como OpenStreetMap migraron a PostGIS, mientras que otros usaban las Oracle Spatial Extensions.
Para ser sinceros, la lista de cambios referentes a GIS parece bastante extensa, y he sido todavía incapaz de echarle un vistazo en detalles. Pero puedo ver que todavía no hay soporte a proyecciones (después de todo, eso requeriría probablemente rehacer por completo esta característica), y con ello, tampoco funciones nativas de distancia, lo cual hace que no sea una alternativa viable a PostGIS en muchos escenarios. Pero tengo que otorgar que el soporte a InnoDB, al menos a nivel de MyISAM y más allá es un gran paso adelante. De nuevo, a veces no necesitas un conjunto de características completo para la mayoría de la audiencia de MySQL, sino un conjunto de opciones mínimas para mostrar de manera eficiente un mapa en una página web.
MyISAM en un mundo post-myisam
En resumen, estos cambios, unidos con una lenta pero segura migración de las tablas de sistema a formato InnoDB, junto con los esfuerzos por reducir la carga transaccionar de las tablas temporales internas, permitirá a Oracle hacer MyISAM opcional en un futuro.
Yo mismo continuaré usando MyISAM en ciertos casos ya que a veces uno no necesita almacenamiento ACID, y funciona particularmente para conjuntos de datos pequeños y de solo lectura -incluso si tienes millones de esos (ey, les funciona a WordPress.com, así que ¿por qué no seguir usándolo también?).
Además, la gente tardará años en adoptar 5.7, que no está ni siquiera en GA release (versión considerada para uso general).
Contadme ¿planeáis migrar de motores cuando 5.7 llegue a tu producción? ¿Para qué sigues usando MyISAM? ¿Cuál es tu característica nueva favorita de 5.7.5? ¿Qué peros habéis encontrado en las nuevas características anunciadas? Dejadme un mensaje aquí o en Twitter.
Mientras realizaba unos tests (que os enseñé posteriormente aquí) en el -todavía en desarrollo- MySQL 5.7 quise hacer un análisis de la configuración para ver si los cambios en el rendimiento eran debidos a los cambios en el código o simplemente a los parámetros por defecto de MySQL (algo que es muy común en una migración de 5.5 a 5.6 debido al tamaño por defecto del log de transacciones y otros parámetros por defecto). Éste es un post rápido con el objetivo de identificar las variables globales que se han modificado entre estas dos versiones.
Me podrían decir que con leer las notas de cambios de versiones (release notes) sería suficiente, pero mi experiencia me dice (y esta no es una excepción, como podréis comprobar) que compruebe los cambios por mí mismo.
No incluyo cambios en las tablas de performance_schema, ya que estaba ejecutando estos tests en particular con performance_schema = OFF. Tampoco incluyo “cambios administrativos”, mi nombre para las variables que no influyen el comportamiento o el rendimiento de mysql, tales como el server_uuid, que será diferente para instancias distintas y version e innodb_version, que obviamente han cambiado de 5.6.20 a 5.7.4-m14. Tenga en cuenta que alguno de los cambios han sido portados de vuelta a 5.6, por lo que no se mostrarán aquí, o ya estaban disponibles en versiones previas de 5.7.
Respecto a potenciales incompatibilidades, todas las variables obsoletas excepto una eran literalmente inútiles, y no las encontraba normalmente configuradas, excepto por innodb_additional_mem_pool_size, la cual era, en mi experiencia, siempre configurada por error, ya que no tenía absolutamente ningún efecto en versiones recientes de InnoDB. La excepción es binlogging_impossible_mode, que fue añadida en 5.6.20 y probablemente no mergeada a tiempo para esta milestone de 5.7. Probablemente sea añadida en el futuro con una funcionalidad equivalente. Una característica interesante, me gustaría añadir.
default_authentication_plugin no es una nueva funcionalidad, tan sólo se ha movido de un parámetro de servidor a una variable global de pleno derecho que puede ser inspeccionada (pero no cambiada) en tiempo de ejecución. El verdadero cambio aquí es default_password_lifetime, que realmente se echaba de menos en 5.6- expiración automática de contraseñas (sin tener que ejecutar manualmente PASSWORD EXPIRE). Lo que encuentro interesante es el valor por defecto: 360 (las contraseñas expiran aproximadamente una vez al año). No estoy diciendo que sea un valor por defecto malo o bueno, pero predigo bastante controversia/confusión sobre eso. Hay más que hablar sobre cambios en la autenticación, pero no me expandiré aquí, ya que no concierne a las variables de configuración.
Algunos añadidos a InnoDB, como por ejemplo la variable innodb_page_cleaners, permitiendo múltiples hilos de ejecución para el flusheo de páginas desde el buffer pool en paralelo, y el cual fue el sujeto de una reciente discusión sobre un cierto benchmark. Además, se ha añadido cierta flexibilidad extra respecto a la configuración del cacheo del log de transacciones y la configuración de la localización de las tablas temporales en formato InnoDB que considero cambios menores como para ir sobre cada uno de ellos en detalle.
log_warnings ha cambiado pero no ha sido documentado. Pero siendo sinceros, su funcionalidad es obsoleta ya que ha sido sustituida por log_error_verbosity, una nueva variable recientemente introducida que hace que por defecto se registren por defecto todos los errores, avisos y notas. He enviado el bug #73745 (arreglado) sobre esto.
Una nueva variable, rbr_exec_mode, parece haberse añadido en 5.7.1, pero no está documentada en ningún sitio de las sección de variables del servidor o en las release notes, tan sólo en el blog de ese desarrollador. Ésta permite iniciar a nivel de sesión un modo IDEMPOTENT cuando se replican eventos en modo filas, ignorando todos los conflictos encontrados. He creado un bug #73744 (arreglado) para esta incidencia.
Ha habido varios cambios en el performance_schema; no comentaré sobre ellos aquí. Tenga en cuenta que performance_schema_max_statement_classes no es un cambio real, ya que se calcula al inicio (no tiene un valor fijo).
En resumen, cambios interesantes, tan sólo una cambio en la configuración por defecto que podría alterar el rendimiento (eq_range_index_dive_limit), y nada que podría crear problemas en una migración, con dos excepciones provenientes de pronósticos propios:
Instancis de la (por otro lado inútil desde hace tiempo, tal y como se mencionaba arriba) variable innodb_additional_mem_pool_size fallando con:
, la cual simplemente debería borrarse del fichero de configuración.
Y el tiempo de expiración establecido por defecto a un año, que podría producir montones de:
ERROR 1862 (HY000): Your password has expired.
o incluso crear algunos problemas difíciles de identificar en conectores anticuados, tal y como hemos experimentado con esta funcionalidad en 5.6. Me gustaría conocer en particular vuestra opinión sobre la configuración por defecto para el expirado de contraseñas en el software, ya que no me considero un experto en seguridad. Como habitualmente, podéis dejarme comentarios aquí o en Twitter.
EDIT: Morgan Tocker, de Oracle, ha comentado via Twitter que “innodb_additional_mem_pool_size no ha tenido utilidad desde hace mucho tiempo (desde el plugin), y que la razón para el cambio ahora son los problemas adicionales de aceptar pero ignorar opciones“. No me quejo de esos cambios, de hecho, creo que deberían haberse mucho tiempo atrás para prevenir esos mismos errores, tan sólo estoy describiendo aquí una solución para lo que creo que serán problemas frecuentes en la migración. La incompatibilidad es a veces la manera correcta.






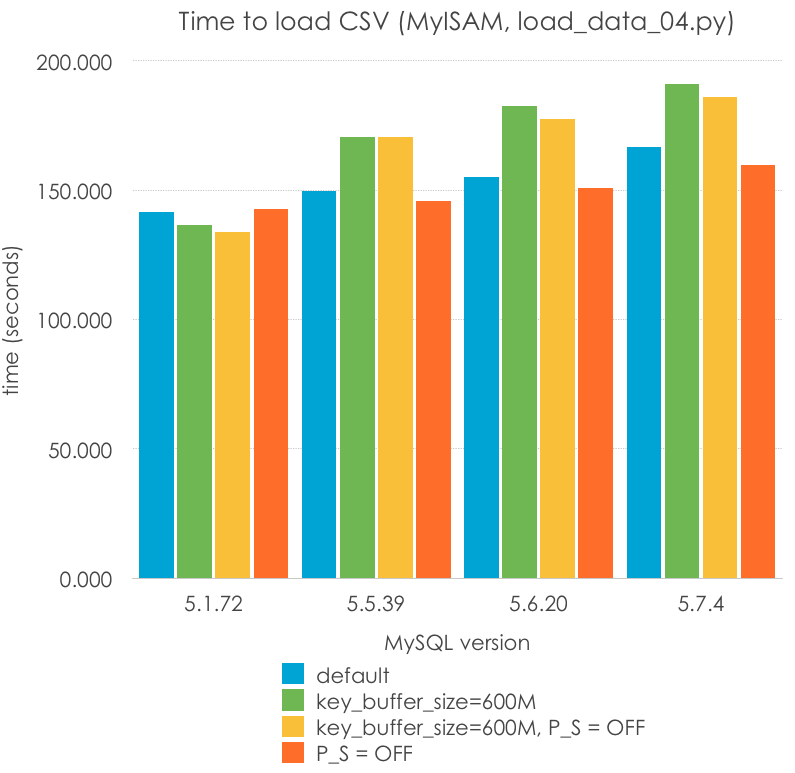



{kind=link}