
On my post last week, I analysed some of the most common compression tools and formats, and its compression speed and ratio. While that could give us a good idea of the performance of those tools, the analysis would be incomplete without researching the decompression. This is particularly true for database backups as, for those cases where the compression process is performed outside of the production boxes, you may not care too much about compression times. In that case, even if it is relatively slow, it will not affect the performance of your MySQL server (or whatever you are using). The decompression time, however, can be critical, as it may influence in many cases the MTTR of your whole system.
Testing environment
I used the same OpenStreetMap node MySQL dump in CSV format that I mentioned on my previous post, and -as some tools used the same format (and they should be compatible), but resulted on different compressed ratio- I chose the smallest resulting file for each of them. Here it is a table with the compressed size per format, as a reminder:
| format | size (bytes) |
| original .csv (no compression) | 3700635579 |
| gzip | 585756379 |
| bzip2 | 508276130 |
| bzip2 (pbzip2-compressed) | 508782016 |
| 7z | 354107250 |
| lzip | 354095395 |
| lzo | 782234410 |
| lz4 | 816582329 |
Please note that while p7zip and lzip/plzip used the same algorithm, the file format is different. Also please notice the usage of two different compressed files for bzip2: the reason for that will be clarified later.
The hardware specs were the same as for the last post: an almost-idle Intel Quad Core i7-3770@3.40GHz with hyper threading, exposing 8 cpus to the kernel. 32 GB of ram. 2 spinning disks of 3 TB in RAID 1. The filesystem type was ext4 with the default OS options. The operating system had changed to CentOS 7, however.
The methodology was similar as before, for each tool, the following command was executed several times:
$ time [tool] -d -c < nodes.csv.[format] > nodes.csv
Except for dd and 7za, where the syntax is slightly different.
The final file was stored on a different partition of the same RAID. The final file was checked for correction (the uncompressed file was exactly the same as the original one) and deleted after every execution. I will not repeat here my disclaimer about the filesystem cache usage, but I also added the dd results as a reference.
Global results
This is my table of final results and the analysis and discussion follows bellow:
method compressed compression median decompression decompression %CPU Usage
size (bytes) ratio (%) time (seconds) speed (MB/s)
dd 3700635579 100.00% 9.996 353.061 100 - 43
gzip 585756379 15.83% 17.391 202.933 99 - 26
bzip2 508276130 13.73% 55.616 63.457 100 - 45
pigz 585756379 15.83% 7.115 496.023 172 - 62
pbzip2 (bzip2-compressed) 508276130 13.73% 50.760 69.527 170 - 64
pbzip2 (pbzip2-compressed) 508782016 13.75% 9.904 356.341 794 - 185
lzip 354095395 9.57% 38.682 91.236 100 - 47
7za 354107250 9.57% 28.070 125.729 157 - 95
plzip 354095395 9.57% 19.791 178.324 345 - 177
lzop 782234410 21.14% 6.094 579.127 136 - 47
lz4 816582329 22.07% 3.176 1111.209 100 - 78
These data can be seen more easily, as usual, on a bidimensional graph. Here the X axis represents the median speed of decompression in MB/s (more is better) and the Y axis represents the compressed ratio in percentage of the compressed size over the original size (less is better):
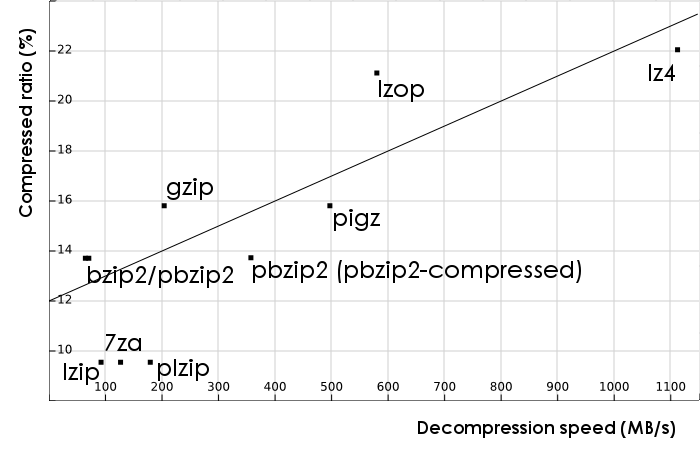
(not plotted: dd, as it would appear with a 100% compression ratio).
CPU usage was polled every second, and so it was the memory usage, that in no test for any of the tools was over 1MB.
In this case I have plotted the function y = x*0.01+12 over the points and, while there is a clear tendency of better compression ratios requiring more time to decompress, the correlation is weaker than on the compression case.
The last thing I want to remark about the global results is that I have not tried variations in parameters for decompression, as in most cases there are little to no options for this process, and the algorithms will do essentially the same for a file that was created with --fast than another created with --best.
Decompressing gzip and bzip2 formats
Unsurprisingly, the gzip file took less time to decompress than bzip with the generic GNU tools (56 seconds vs. 17). I used GNU gzip 1.5 and bzip2 1.0.6. I said everything I had to say about the advantages and disadvantages of using the most standard tools, so I will not repeat myself, but I wanted to reiterate the idea that gzip is a great tool for fast compression processes when there is not an alternative, as it got a mean throughput of almost 203 MB/s when decompressing our test file.
Of course, the next step was testing decompressing in parallel, and for that I had pigz 2.3.1 and pbzip2 v1.1.6. As a side note, I would like to mention that, at the time of this writing, there were no rpm packages for pbzip2 for CentOS 7 in the base distribution nor on EPEL (which is currently in beta for version 7). I used the package for RHEL6.
However, when looking at the pigz results we can realise that, while there is certainly an improvement on speed (just over 7 seconds), it is not as dramatic as the 4x+ improvement that we had on compression. Also, if we look at the cpu usage, we can realise that the maximum %CPU usage is never over 170. I found the reason for that while looking at the documentation: while pigz uses several threads for read and write I/O, it is unable to parallelise the core gzip decompression algorithm. The improvement over standard gzip -however- is there, with almost 500 MB/s of decompression bandwidth.
When checking pbzip2, on my first try, I realised that there was no parallelization at all, and that the timing results were essentially the same as with regular bzip2. I searched for answers on the documentation and I found that and the reason for that was that decompression in parallel was possible (unlike gzip), but only for files created by pbzip2 itself. In other words, both bzip2 and pbzip2 create files with a compatible format (they can be decompressed with each other), but parallelization is only fully possible if they are created and decompressed with pbzip2. To test that second case, I got the best-compressed file that I got from my previous results (which was slightly larger than the one created with bzip2) and retried the tests. That is why there are two different rows on the global results for pbzip2.
In that second scenario, pbzip2 was a real improvement over bzip2, obtaining decompression rates of 356 MB/s, roughly equivalent to the results of a raw filesystem copy.
As it was expected, multiple threads of decompression is a clear advantage on SMP systems, with the usual disclaimers of extra resources consumed and the fact that, as just seen, it is not possible for all file formats.
Lzma decompression
The next group to test is lzma-based tools: Lzip 1.7, p7zip 9.20 and plzip 1.2-rc2. Again, lzip was not available on EPEL-7, and the RedHat6 version was used, and plzip was compiled from source, as we had to do previously.
Lzma algorithm was classified as a slow but good-compression algorithm on our previous results. A similar thing can be extrapolated for decompression: both lzip and 7za provide decompression times of around 30 seconds, with throughputs near the 100 MB/s. Although p7zip seems to be a bit better paralleled than lzip (with %cpu usage reaching 150), both provide essentially a mono-thread decompression algorithm. Plzip provides a better parallelization, reaching a maximum %cpu of 290, but the throughput never reaches the 200 MB/s.
The general evaluation is that they are clearly better tools than single-threaded gzip and bzip2, as they provide similar decompression bandwidths but with much better compression ratios.
Fast tools: lzop and lz4
Finally, we have left the fast compression and decompression tools, in our tests lzop v1.03 and lz4 r121. In this case we can testify the the claims that lz4, while providing similar compression speed than lzop, it is faster for decompression: almost doubling the rate (580 MB/s for lzop vs. 1111 MB/s for lz4). Obviously, the only reason those results are possible is because the filesystem cache is kicking in, so take this results with the due precaution. But it shows what kind of decompression bandwidth can be achieved when the disk latency is not the bottleneck.
When the time of the test is so small, I would recommend repeating it with larger filesizes and/or limiting the effect of the filesystem cache. I will leave that as a homework for the reader.
Conclusion
Aside from the found limitations of several of the tools regarding decompression parallelization (pigz, pbzip2), no highly surprising results have been found. Fast compression tools are fast to decompress (I have become a fan of lz4) and best-compression tools are slower (plzip seems to work very well if we are not constrained by time and CPU). As usual, I will leave you with my recommendation of always testing on your environment, with your own files and machines.
Which compression tool(s) do you use for MySQL (or any other database backups)? Leave me a comment here or on Twitter.