I am happy that the MySQL team is, during the last years, blogging about each major feature that MySQL Server is getting; for example, the series on RecursiveCommonTableExpressions. Being extremely busy myself, I appreciate taking the time to share details with the advantage of getting an “insider” point of view.
However, first party guides and examples can be seen at times as not terrible useful at first- as normally they are done with synthetic, artificial examples and not real-life ones. I want to share with you 2 examples of how 2 of the upcoming features of MySQL 8.0 will be useful to us, with examples that we already use or plan to use for the Wikimedia Foundation databases: roles and recursive CTEs.
Roles
Giusseppe “data charmer” Maxia presented recently at FOSDEM 2018 how the newly introduced roles are going work (you can watch and read his presentation at the FOSDEM website) and he seemed quite skeptical about the operational side of it. I have to agree -some of the details are not straightforward as how users and roles work on other environments, but I have to say we have been using database roles for a while with MariaDB without any problems in the last year.
User roles were introduced on MariaDB 10.0, although for us they were unusable until MariaDB 10.1, and its implementation seems to be similar, if not exactly the same as that of MySQL 8.0 (side note. I do not know why that is ̣—is it an SQL standard? Was the implementation inspired by Oracle or other famous database? does it have a common origin? Please tell me in the comments if you know the answer).
If you use MySQL for a single large web-like application, roles may not be very useful to you. For example, for the Mediawiki installation that supports Wikipedia, only a few accounts are setup per database server -one or a few for the application, plus those needed for monitoring, backups and administration (please do not use a single root account for all in yours!).
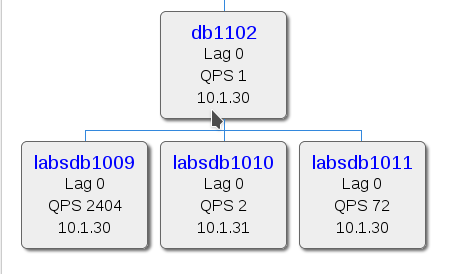
LabsDB databases provided a vital service to the community by providing direct access to community-accessible database replicas of production data.
However, we also provide free hosting and other IT services for all developers (including volunteers) to create webs, applications and gadgets that could be useful to the full Wikimedia community. Among those services, we have a data service where we provide a replica of a sanitized database with most of the data of the production mediawiki installation, plus additional database accounts to store their own application data. This requires a highly multi-tiered MySQL/MariaDB installation, with thousands of accounts per server. In the past, each account had to be managed separately, with its own grants and accounts limits- this was a nightmare, and the little accountability could easily lead to security issues. Wildcards were used to assign grants, which was a really bad idea- because wildcards not only provide grants to current databases, also to future databases that match the pattern- and that is very dangerous- wrong data sets could accidentally end up on the wrong servers and all users would get automatically access. Also, every time there was some kind of maintenance where all users had to be added or revoked certain grant (not frequent, but could happen), a script had to be run to do that in a loop for each account. Also, there are other accounts aside from user accounts (the administration and monitoring ones), but aside from a specific string pattern, there was no way to differentiate user from administration or monitoring accounts.
Our cloud databases were the first we upgraded to MariaDB 10.1 exclusively to get a transparent role implementation (SET default role). We created a template role (e.g. ‘labsdbuser‘), which all normal users will be granted to (you can see the actual code on our puppet repo):
GRANT USAGE ON *.* TO ...;
GRANT labsdbuser TO ;
SET DEFAULT ROLE labsdbuser FOR ;
, and because it is so compact, we can give a detailed, non-wildcard-based selection of grants to to the labsdbuser generic role.
If we had to add a new grant (or revoke it) to all users, we just have to run:
GRANT/ REVOKE TO / FROM labsdbuser;
only once per server, and all users affected will get it automatically (well, they have to log off and on, but that was true of any grant).
Can the syntax be simpler or the underlying tables confusing? Sure, but in practice -at least for us-, we rarely have to handle role changes- they don’t tend to be very dynamic. However, it simplified a lot the creation, accountability, monitoring and administration of user accounts for us.
Recursive CTEs
CTEs are one of the other large syntactic sugar added on 8.0 (they were also added on MariaDB 10.2). Unlike the roles, however, this is something that application developers will benefit from -roles are mostly helpful for Database Administrators.
As I mentioned before, we have upgraded our servers at most to MariaDB 10.1 (stability is very important for us), so I have not yet been able to play on production with them. Also, because Mediawiki has to support older applications, it might take years to see those being used on web requests for wikis. I see them, however, being interesting first for analytics and for the cloud community applications I mentioned previously.
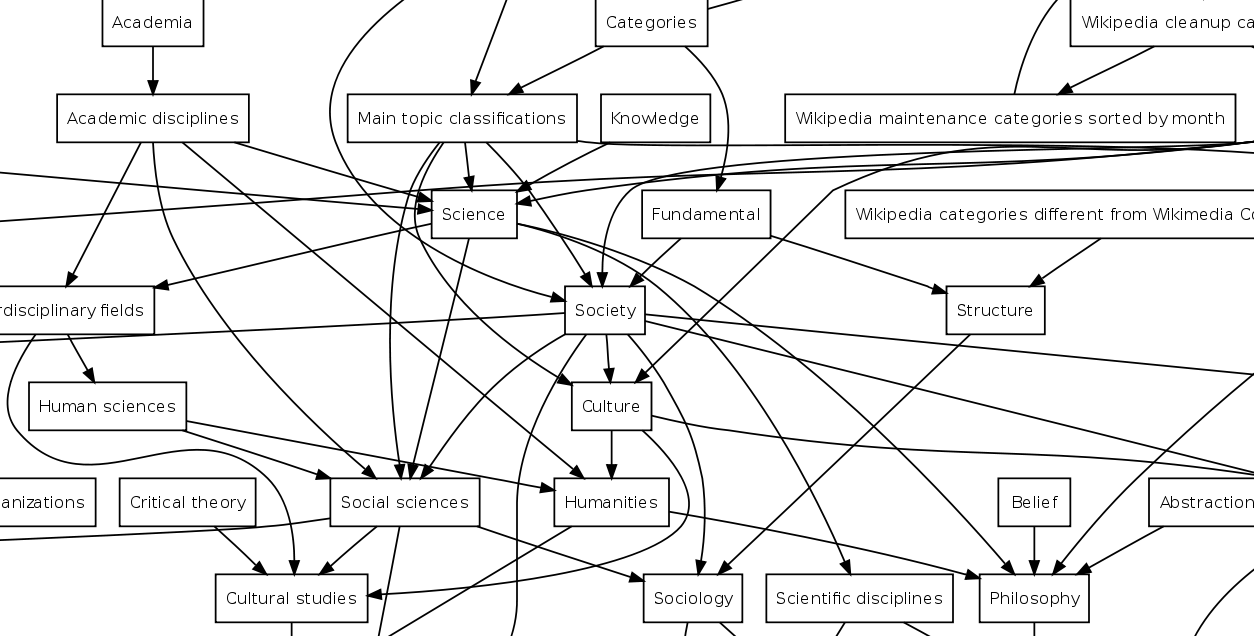
Mediawiki has some hierarchical data stored on their tables; probably the most infamous one is the category tree. As of 2018 (this may change in the future), the main way to group Wiki pages and files is by using categories. However, unlike the concept of tags, categories may contain other more specialized categories.
Mediawiki/Wikipedia category system can become quite complex. Image License: CC-BY-SA-3.0 Author: Gurch at English Wikipedia
However, if you go to the category Database management systems, you will not find it there, because you have to browse first thought Database management systems > Relational database management systems > MySQL; or maybe Database management systems > Database-related software for Linux > RDBMS software for Linux > MySQL
The relationship between pages and categories are handled on the classical “(parent, child) table” fashion, the categorylinks table, which has the following structure:
CREATE TABLE /*_*/categorylinks (
-- Key to page_id of the page defined as a category member.
cl_from int unsigned NOT NULL default 0,
-- Name of the category.
-- This is also the page_title of the category's description page;
-- all such pages are in namespace 14 (NS_CATEGORY).
cl_to varchar(255) binary NOT NULL default '',
...
PRIMARY KEY (cl_from,cl_to)
) /*$wgDBTableOptions*/;
CREATE INDEX /*i*/cl_sortkey ON /*_*/categorylinks (cl_to,cl_type,cl_sortkey,cl_from);
The table has been simplified, we will not get on this post into collation issues- that would be material for other separate discussion. Also ignore the fact that cl_to links to a binary string rather than an id, there are reasons for all of that, but cannot enter into details now.
However, if you want to answer the question “Give me all articles in a particular category or its subcategories”, this structure is not well suited to answer this question. Or at least it didn’t use to be, for older versions of MySQL and MariaDB. Alternative table design structures have been proposed in the past (both for Mediawiki and for the general problem) to solve this commonly found structure, but not all will be a applicable, as the Wiki category system is very flexible, and not even strictly a tree- it can contain, for example, loops.
Up to now, custom solutions, such as this answer on stackoverflow, or specially-built applications, such as: Petscan, had to be developed to provide lists of articles queried recursively.
Again, enter recursive CTEs. Instead of having to use external code to apply recursion, or an awkward stored procedure, we can just send the following sql:
WITH RECURSIVE cte (cl_from, cl_type) AS
(
SELECT cl_from, cl_type FROM categorylinks WHERE cl_to = 'Database_management_systems' -- starting category
UNION
SELECT categorylinks.cl_from, categorylinks.cl_type FROM cte JOIN page ON cl_from = page_id JOIN categorylinks ON page_title = cl_to WHERE cte.cl_type = 'subcat' -- subcat addition on each iteration
)
SELECT page_title FROM cte JOIN page ON cl_from = page_id WHERE page_namespace = 0 ORDER BY page_title; -- printing only articles in the end, ordered by title
It looks more complicated than it should, because we need to join with the page table in order to get page ids from titles; but otherwise the idea is simple: get a list of pages, if they are subcategories, query them recursively, otherwise, add them to the list. By using UNION instead of UNION ALL we make sure we do not explore the same subcategory twice. Note how we end up with a list larger than the 143 items are directly on the category.
If we fall in an infinite loop, or a very deep chain of relationships, the variable limiting the number of executions, cte_max_recursion_depth can be tuned. By default it fails if we do 1001 iterations.
So tell me, do you think these or other recently-added features will be as useful for you as the seem to be for us? What is your favourite one recently added to MySQL or MariaDB? Send me a comment or a message to @jynus.
Intel(R) Core(TM) i7-4790K CPU @ 4.0GHz (x86_64 Quad-core with hyperthreading) with PCID support (disabling pcid with “nopcid” kernel command line will also be tested)
4.9.0-4-amd64 #1 SMP Debian 4.9.65-3+deb9u1 (no mitigation)
4.9.0-5-amd64 #1 SMP Debian 4.9.65-3+deb9u2 (latest kernel with security updates backported, including pti enabled according to security-announces)
datadir formatted as xfs, mounted with noatime option, all on top of LVM
MariaDB Server 10.1.30 compiled from source, queried locally through unix socket
The tests performed:
The single-thread write with LOAD DATA
A read-only sysbench with 8 and 64 threads
The results
LOAD DATA (single thread)
We have been measuring LOAD DATA performance of a single OpenStreetMap table (CSV file) in severalprevious tests as we detected a regression on some MySQL versions with single-thread write load. I believe it could be a interesting place to start. I tested both the default configuration and another more similar to WMF production:
Load time
rows/s
Unpatched Kernel, default configuration
229.4±1s
203754
Patched Kernel, default configuration
227.8±2.5s
205185
Patched Kernel, nopcid, default configuration
227.9±1.6s
205099
Unpatched Kernel, WMF configuration
163.5±1s
285878
Patched Kernel, WMF configuration
163.3±1s
286229
Patched Kernel, nopcid, WMF configuration
165.1±1.3s
283108
No meaningful regressions are observed in this case between the default patched and unpatched kernels- the variability is within the measured error. The nopcidcould be showing some overhead, but the overhead (around 1%) is barely above the measuring error. The nopcid option is interesting not because the hardware support, but because of the kernel support- backporting it could be a no-option for older distro versions, as Moritz says on the comments.
It is interesting to notice, although offtopic, that while the results with the WMF “optimized” configuration have become better compared to previous years results (due, most likely, to improved CPU and memory resources); the defaults have become worse- a reminder that defaults are not a good metric for comparison.
This is not a surprising result, a single thread is not a real OLTP workload, and more time will be wasted on io waits than the necessary syscalls.
RO-OLTP
Let’s try with a different workload- let’s use a proper benchmarking tool, create a table and perform point selects with it, with 2 different levels of concurrency- 8 threads and 64 threads:
In this case we can observe around a 4-7% regression in throughput if pcid is enabled. If pcid is disabled, they increase up to 9-10% bad, but not as bad as the warned by some “up to 20%”. If you are in my situation, and upgrade to stretch would be worth to get the pcid support.
Further testing would be required to check at what level of concurrency or what kind of workloads will work better or worse with the extra work for context switch. It will be interesting to measure it with production traffic, too, as some of the above could be nullified when network latencies are added to the mix. Further patches can also change the way mitigation works, plus probably things like having PCID support is helping transparently on all modern hardware.
Have you detected a larger regression? Are you going to patch all your databases right away? Tell me at @jynus.
In the latest stable version of Debian, if you ask to install mysql-server, you now get installed mariadb automatically, with no (evident) way of installing Oracle’s MySQL. Any major version upgrade has to be done carefully (not only for MariaDB, but also for MySQL and Postgres), and I bet that a MySQL 5.5 to MariaDB 10.1 will cause a huge confusion. Not only it will fail user expectations, I think this will cause large issues now that MariaDB has chosen to become a “hard” fork, and become incompatible in many ways with MySQL. Not only the server upgrade will cause user struggle, the connector is probably going to cause pain to users (as it has already been noticed in some of my infrastructure).
In order to try to be helpful for those MySQL users that may be looking for help, here is how to install and setup MySQL server in Debian 9 “Stretch”, using MySQL upstream repo. The commands shown above may not be the best course of action on all cases (be careful when downloading things from then Internet), and as a disclaimer, you should read the official documentation on how to use Oracle’s MySQL apt repository in advance. The following is a more verbose, step-by step explanation, plus some extended explanations on why I chose to recommend this method in particular (and its disadvantages).
Install Oracle’s APT Repositories
MySQL Release Engineering team provides ready-to-use apt repositories with most of it software, including the server and many of its utilities. To enable the server repository, edit your apt sources file (or better, create a new one by executing:
# nano /etc/apt/sources.list.d/mysql.list
And add the following lines:
deb http://repo.mysql.com/apt/debian/ stretch mysql-5.7
deb-src http://repo.mysql.com/apt/debian/ stretch mysql-5.7
Here, I have chosen to install MySQL 5.7, but 5.6 and 8.0 (not yet stable as of June 2017) are also available for Debian stable. You can also chose to enable mysql-tools (normally here they add the connectors, mysql-router and the mysql-utilities, but right now it is empty) and mysql-apt-config the repo where the automatic apt configurator package is. While the mysql-apt-config utility is nice to have, I like to have control over my repositories manually, even if that means having to do this again in the future.
Before starting to use the repo, you have to add the repo public key as trusted, for that I suggest:
RPM and APT repos seem to share the GPG key, and that is at https://repo.mysql.com/RPM-GPG-KEY-mysql (it is the same one that mysql-apt-config utility adds automatically on install). Not doing so will not make the rest of the install fail, but it will warn you due to the lack of a signed key.
If you run apt-key list you will see a new trusted key for apt:
The advantages of using a repository rather than a one-time install is that you will get automatic updates for minor versions that may correct bugs and security issues (with minimal feature changes).
Refresh your available package list
Just run:
# apt update
Ign:1 http://softlibre.unizar.es/debian stretch InRelease
Hit:2 http://softlibre.unizar.es/debian stretch-updates InRelease
Hit:3 http://security.debian.org/debian-security stretch/updates InRelease
Hit:4 http://softlibre.unizar.es/debian stretch Release
Get:5 http://repo.mysql.com/apt/debian stretch InRelease [14.2 kB]
Get:7 http://repo.mysql.com/apt/debian stretch/mysql-5.7 Sources [870 B]
Get:8 http://repo.mysql.com/apt/debian stretch/mysql-5.7 amd64 Packages [5,643 B]
Fetched 20.7 kB in 6s (3,320 B/s)
Reading package lists... Done
Building dependency tree
Reading state information... Done
All packages are up to date.
You should see a reference to repo.mysql.com with no errors. You probably have other main repos or pending updates, that is ok.
Install MySQL Server:
# apt install mysql-server
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following additional packages will be installed:
libaio1 libatomic1 libmecab2 libnuma1 mysql-client mysql-community-client
mysql-community-server
The following NEW packages will be installed:
libaio1 libatomic1 libmecab2 libnuma1 mysql-client mysql-community-client
mysql-community-server mysql-server
0 upgraded, 8 newly installed, 0 to remove and 0 not upgraded.
Need to get 36.7 MB of archives.
After this operation, 253 MB of additional disk space will be used.
Do you want to continue? [Y/n] Y
Get:1 http://repo.mysql.com/apt/debian stretch/mysql-5.7 amd64 mysql-community-client amd64 5.7.18-1debian9 [8,859 kB]
Get:2 http://softlibre.unizar.es/debian stretch/main amd64 libaio1 amd64 0.3.110-3 [9,412 B]
Get:3 http://softlibre.unizar.es/debian stretch/main amd64 libatomic1 amd64 6.3.0-18 [8,920 B]
Get:4 http://softlibre.unizar.es/debian stretch/main amd64 libnuma1 amd64 2.0.11-2.1 [33.3 kB]
Get:5 http://softlibre.unizar.es/debian stretch/main amd64 libmecab2 amd64 0.996-3.1 [256 kB]
Get:6 http://repo.mysql.com/apt/debian stretch/mysql-5.7 amd64 mysql-client amd64 5.7.18-1debian9 [12.6 kB]
Get:7 http://repo.mysql.com/apt/debian stretch/mysql-5.7 amd64 mysql-community-server amd64 5.7.18-1debian9 [27.5 MB]
Get:8 http://repo.mysql.com/apt/debian stretch/mysql-5.7 amd64 mysql-server amd64 5.7.18-1debian9 [12.6 kB]
Fetched 36.7 MB in 4s (8,495 kB/s)
Preconfiguring packages ...
Selecting previously unselected package libaio1:amd64.
(Reading database ... 27516 files and directories currently installed.)
Preparing to unpack .../0-libaio1_0.3.110-3_amd64.deb ...
Unpacking libaio1:amd64 (0.3.110-3) ...
Selecting previously unselected package libatomic1:amd64.
Preparing to unpack .../1-libatomic1_6.3.0-18_amd64.deb ...
Unpacking libatomic1:amd64 (6.3.0-18) ...
Selecting previously unselected package libnuma1:amd64.
Preparing to unpack .../2-libnuma1_2.0.11-2.1_amd64.deb ...
Unpacking libnuma1:amd64 (2.0.11-2.1) ...
Selecting previously unselected package mysql-community-client.
Preparing to unpack .../3-mysql-community-client_5.7.18-1debian9_amd64.deb ...
Unpacking mysql-community-client (5.7.18-1debian9) ...
Selecting previously unselected package mysql-client.
Preparing to unpack .../4-mysql-client_5.7.18-1debian9_amd64.deb ...
Unpacking mysql-client (5.7.18-1debian9) ...
Selecting previously unselected package libmecab2:amd64.
Preparing to unpack .../5-libmecab2_0.996-3.1_amd64.deb ...
Unpacking libmecab2:amd64 (0.996-3.1) ...
Selecting previously unselected package mysql-community-server.
Preparing to unpack .../6-mysql-community-server_5.7.18-1debian9_amd64.deb ...
Unpacking mysql-community-server (5.7.18-1debian9) ...
Selecting previously unselected package mysql-server.
Preparing to unpack .../7-mysql-server_5.7.18-1debian9_amd64.deb ...
Unpacking mysql-server (5.7.18-1debian9) ...
Setting up libatomic1:amd64 (6.3.0-18) ...
Setting up libnuma1:amd64 (2.0.11-2.1) ...
Setting up libmecab2:amd64 (0.996-3.1) ...
Processing triggers for libc-bin (2.24-11+deb9u1) ...
Setting up libaio1:amd64 (0.3.110-3) ...
Processing triggers for systemd (232-25) ...
Processing triggers for man-db (2.7.6.1-2) ...
Setting up mysql-community-client (5.7.18-1debian9) ...
Setting up mysql-client (5.7.18-1debian9) ...
Setting up mysql-community-server (5.7.18-1debian9) ...
Setting up mysql-server (5.7.18-1debian9) ...
Processing triggers for libc-bin (2.24-11+deb9u1) ...
If everything has gone according to plan, after asking you for permission to install it and its dependencies, you should have NOT installed mariadb-server, but the real mysql server instead. If at some stage you got an error, check your spelling or your permissions- all of the above steps should have been run with superuser or root permissions, and not as a normal user. That means using sudo before each command, su -c CMD or logging in as root in advance.
These MySQL packages initialize and start MySQL server by default:
# systemctl status mysql
● mysql.service - MySQL Community Server
Loaded: loaded (/lib/systemd/system/mysql.service; enabled; vendor preset:
Active: active (running) since Sun 2017-06-25 12:16:50 PDT; 31min ago
Process: 4399 ExecStart=/usr/sbin/mysqld --daemonize --pid-file=/var/run/my
Process: 4362 ExecStartPre=/usr/share/mysql/mysql-systemd-start pre (code=e
Main PID: 4401 (mysqld)
Tasks: 27 (limit: 4915)
CGroup: /system.slice/mysql.service
└─4401 /usr/sbin/mysqld --daemonize --pid-file=/var/run/mysqld/mys
Jun 25 12:16:50 debian mysqld[4399]: 2017-06-25T19:16:50.342805Z 0 [Note] IPv
Jun 25 12:16:50 debian mysqld[4399]: 2017-06-25T19:16:50.345596Z 0 [Note] -
Jun 25 12:16:50 debian mysqld[4399]: 2017-06-25T19:16:50.348320Z 0 [Note] Ser
Jun 25 12:16:50 debian mysqld[4399]: 2017-06-25T19:16:50.421804Z 0 [Note] Eve
Jun 25 12:16:50 debian mysqld[4399]: 2017-06-25T19:16:50.426584Z 0 [Note] /us
Jun 25 12:16:50 debian mysqld[4399]: Version: '5.7.18' socket: /var/run/mysq
Jun 25 12:16:50 debian mysqld[4399]: 2017-06-25T19:16:50.430667Z 0 [Note] Exe
Jun 25 12:16:50 debian mysqld[4399]: 2017-06-25T19:16:50.430739Z 0 [Note] Beg
Jun 25 12:16:50 debian mysqld[4399]: 2017-06-25T19:16:50.531384Z 0 [Note] End
Jun 25 12:16:50 debian systemd[1]: Started MySQL Community Server
You can manage the service with service wrapper or with the native systemd command. Remember that it is possible that earlier os versions had a package that still used backwards init.d compatibility- it is not the case anymore. However, execution of /etc/init.d/mysql will be captured and converted transparently into an equivalent systemctl command. But get accustomed to say goodbye to the horrible mysqld_safe script and its options (but also its vulnerabilities).
# systemctl restart mysql
# systemctl reload mysql
Failed to reload mysql.service: Job type reload is not applicable for unit mysql.service.
See system logs and 'systemctl status mysql.service' for details.
# systemctl status mysql
● mysql.service - MySQL Community Server
Loaded: loaded (/lib/systemd/system/mysql.service; enabled; vendor preset:
Active: active (running) since Sun 2017-06-25 12:55:43 PDT; 18s ago
Process: 4522 ExecStart=/usr/sbin/mysqld --daemonize --pid-file=/var/run/my
Process: 4485 ExecStartPre=/usr/share/mysql/mysql-systemd-start pre (code=e
Main PID: 4524 (mysqld)
Tasks: 27 (limit: 4915)
CGroup: /system.slice/mysql.service
└─4524 /usr/sbin/mysqld --daemonize --pid-file=/var/run/mysqld/mys
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.670560Z 0 [Note] IPv
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.673504Z 0 [Note] -
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.674863Z 0 [Note] Ser
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.750799Z 0 [Note] Eve
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.755752Z 0 [Note] /us
Jun 25 12:55:43 debian mysqld[4522]: Version: '5.7.18' socket: /var/run/mysq
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.755892Z 0 [Note] Exe
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.755929Z 0 [Note] Beg
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.863316Z 0 [Note] End
Jun 25 12:55:43 debian systemd[1]: Started MySQL Community Server.
# journalctl -u mysql
Jun 25 12:55:41 debian systemd[1]: Stopped MySQL Community Server.
Jun 25 12:55:41 debian systemd[1]: Starting MySQL Community Server...
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.028273Z 0 [Warning]
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.038562Z 0 [Note] /us
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.076552Z 0 [Note] Inn
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.080224Z 0 [Note] Inn
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.080428Z 0 [Note] Inn
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.080508Z 0 [Note] Inn
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.080651Z 0 [Note] Inn
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.080739Z 0 [Note] Inn
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.094601Z 0 [Note] Inn
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.096806Z 0 [Note] Inn
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.116165Z 0 [Note] Inn
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.201413Z 0 [Note] Inn
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.215069Z 0 [Note] Inn
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.241133Z 0 [Note] Inn
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.325375Z 0 [Note] Inn
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.329688Z 0 [Note] Inn
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.484928Z 0 [Note] Inn
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.496504Z 0 [Note] Inn
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.499790Z 0 [Note] Inn
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.506852Z 0 [Note] Inn
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.563491Z 0 [Note] Inn
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.570659Z 0 [Note] Inn
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.573444Z 0 [Note] Plu
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.603637Z 0 [Note] Inn
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.637102Z 0 [Note] Fou
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.646241Z 0 [Warning]
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.666576Z 0 [Note] Ser
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.670560Z 0 [Note] IPv
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.673504Z 0 [Note] -
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.674863Z 0 [Note] Ser
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.750799Z 0 [Note] Eve
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.755752Z 0 [Note] /us
Jun 25 12:55:43 debian mysqld[4522]: Version: '5.7.18' socket: /var/run/mysq
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.755892Z 0 [Note] Exe
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.755929Z 0 [Note] Beg
Jun 25 12:55:43 debian mysqld[4522]: 2017-06-25T19:55:43.863316Z 0 [Note] End
Jun 25 12:55:43 debian systemd[1]: Started MySQL Community Server.
Use your server
This package sets up socket_authentication automatically for the user root, so no need to setup a password- accessing as the root unix user to the mysql root user will be directly granted:
# mysql -u root
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 3
Server version: 5.7.18 MySQL Community Server (GPL)
Copyright (c) 2000, 2017, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> SELECT current_user();
+----------------+
| current_user() |
+----------------+
| root@localhost |
+----------------+
1 row in set (0.00 sec)
The default configuration binds the server to 127.0.0.1, you may want to setup your users and bind it to a public address before put it into production. Config can be found at: /etc/mysql/mysql.conf.d/mysqld.cnf.
Please use @jynus to tell me if this was useful to you, or to tell me where I am wrong.
I’ve been lately compiling and generating .deb packages for several MySQL and MariaDB recent versions, and I wanted to try them more in depth -specially MySQL 8.0 and MariaDB 10.2, both of which are still in development.
Several people have already given their first impressions (or will do soon), and testing early is the best way to catch bugs and regressions, and get them fixed before the official release. In fact, as I will comment later, I ran into breaking bugs on both MySQL 8.0 and MariaDB 10.2, which I immediately reported or joined others on the bug report.
Very recently, there was a call for better MySQL benchmarks, and I cannot agree more with the general idea. However, I have to make some disclaimers: the following are “tests results”, closer to regression testing than to benchmarking. Benchmarking is hard, and I do not have the time or the resources to do them properly and extensively. What I wanted to do is to do a very specific test of a very specific operation (LOAD DATA in a single thread) under very specific circumstances/configuration [in some cases, bad configuration practices] to see if a previously-occurred problem was still there. This is not a mere thought experiment, it will help me tune better the import/backup recovery process, and did allow me get familiarized with the newest versions’ particular idiosyncrasies. Clearly, as you will discover, I do not yet know how to tune the latest unreleased versions, (who knows at this point), so join me on the discovery process.
Secondly, the test I will be doing (LOAD DATA) did not include secondary indexes or JOINs. Again, this will test import times, but not other more common operations like point selects, updates and range selects. Thirdly, I am comparing both Generally Available (stable) versions and versions still in development. The latter can change a lot between now and the release date. I repeat again: This will be in no way representative of the overall performance of MySQL or MariaDB versions. If you get away with the idea that “X is better than Y” based on a chart shown here, you will probably be very wrong. You have been warned.
I hope, however, that some of these results will be helpful to some fellow DBAs and MySQL/MariaDB users and develpers, and that is why I am sharing them early. You may also help me explain some of the results I am getting, which I may not 100% understand yet.
The setup
Server versions:
Oracle MySQL 5.6.34
Oracle MySQL 5.7.16
Oracle MySQL 8.0.0-dmr (not “generally available”)
MariaDB Server 10.0.28
MariaDB Server 10.1.19
MariaDB Server 10.2.2 (non “generally available”)
All versions were compiled from the source code downloaded from its official website with the recommended options (-DBUILD_CONFIG=mysql_release).
Hardware (desktop grade- no Xeon or a proper RAID setup):
Intel(R) Core(TM) i7-4770K CPU @ 3.50GHz (x86_64 Quad-core with hyperthreading)
16 GB of RAM
Single, dektop-grade, Samsung SSD 850 PRO 512GB
OS and configuration:
Debian GNU/Linux 8.6 “Jessie”
datadir formatted as xfs, mounted with noatime option, all on top of LVM
Several server configurations where used, commented on each individual test.
Dataset:
I used again the nodes.csv I used last time, a 3,700,635,579-byte text (tab-separated) file containing 46,741,126 lines (rows) with an old OSM node data dump for Spain:
Setting up the server for the first time in MySQL and MariaDB has now differed. While MariaDB continues using the mysql_install_db script, MySQL, since 5.7, uses the mysqld server binary directly. Also, while I have to thank Oracle for focusing on security, if you are going to setup a server just for pure testing, the default account creation options can be a bit annoying. I have to say thanks because there is an additional `–initialize-insecure` which simplifies the setup for one-time setups like this benchmark or a jenkins test, and that you probably should not be using on a proper production. Maybe it could be helpful for automatic deploys, where accounts are taken care by a script.
For MySQL, I found a problem in 8.0.0 in which mysqld --initializedid not work with binary collations (neither it started if I did the initialization with the default collation, and then started the server with binary as the default encoding). The error I got was:
mysqld: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘binary’ at line 1 [ERROR] Data Dictionary initialization failed.
Binary collation is very important for Wikipedias, because some time ago (and even recently, with the latest extensions to the standard) full Unicode support was difficult to get -and we need to support 300 languages. Also, we have certain needs like custom collations support (e.g. several collations on the same table, numeric sorting). As a consequence of that, most text data is now stored in raw binary. For these tests, I had to disable the binary character for some tests for 8.0.0, which I have appropriately noted it below.
For MariaDB, I ran into an issue that had already been reported (MDEV-10540), in which mysql_install_dbgot hanged if the log_bin option was enabled. While this bug could be workarounded by doing so just for the installation, the option is so common and important that I think the issue should be solved as soon as possible.
I also run into MDEV-1124, MariaDB Server promoting an external business, a mistake which hopefully will be fixed by the release of 10.1.20.
In order to perform the tests, I had to destroy and recreate the datadir, starting from scratch on each run (rm + --initialize). This is also a testimony that you no longer have binary compatibility between server vendors, due to the differences on the mysql schema, performance schema tables, the new data dictionary, etc.
Another thing to notice is that, because of the latest security patches, you have to enable explicitly the secure_file_priv in order to use the LOAD DATA query. You probably do not want to do that on a production server, more details about the issue on CVE-2016-6662 and the other recently related issues.
Default config testing
While testing with the default config is the #1 sin one could do while doing benchmarking (because you are testing the vendor defaults, not a real performance comparison), my test is silly and simple enough for this to be interesting, and spending some time there. Long gone are the times in which MySQL’s defaults were horrible, and Oracle seems very focused lately on trying to setup good defaults that would be useful for the majority of people. But let’s also be honest, these options (together with what packagers setup) are also the ones that 90% of the mysql users out there will use because they are not running dedicated services that require a lot of tuning nor have a dedicated DBA to do it.
So I went and setup mysql with just a bunch of administrative options. In particular I would like to note that by default:
No binary log enabled in all versions
Default buffer pool size is 134217728 for all versions
innodb_log_file_size defaults to 50MB
[client]
port = 3306
socket = /tmp/mysql.sock
[mysqld]
# administrative options
user = mysql
socket = /tmp/mysql.sock
port = 3306
datadir = /srv/sqldata
basedir = /opt/mysql # mysql is a symbolic link to each basedir
tmpdir = /srv/tmp
# prevent imports/exports to arbitrary dirs
secure_file_priv = /tmp
Some interesting config differences between 5.6 and MariaDB 10.0 to have into account: performance schema is disabled on MariaDB, and many buffers and caches have different size
Some interesting config differences between MySQL 5.7 and MySQL 8.0: Innodb removed innodb_file_format and innodb_large_prefix (deprecated in 5.7), only allowing Antilope format for backwards compatibility ( thanks Morgo and Jörg Brühe for the correction). Also, some extra variables related to the new data dictionary.
< # This is MySQL 5.7
> # This is MySQL 8.0
93c93
< ignore_db_dirs
---
> information_schema_stats CACHED
122d121
< innodb_checksums ON
136,138d134
< innodb_file_format Barracuda
< innodb_file_format_check ON
< innodb_file_format_max Barracuda
143c139
< innodb_flush_method
---
> innodb_flush_method fsync
163d158
< innodb_large_prefix ON
165d159
< innodb_locks_unsafe_for_binlog OFF
208d201
< innodb_stats_sample_pages 8
213d205
< innodb_support_xa ON
331a324
> performance_schema_error_size 1043
348c341
< performance_schema_max_memory_classes 320
---
> performance_schema_max_memory_classes 350
354c347
< performance_schema_max_rwlock_classes 40
---
> performance_schema_max_rwlock_classes 50
360c353
< performance_schema_max_statement_classes 193
---
> performance_schema_max_statement_classes 201
370a364
> persisted_globals_load ON
404a399
> schema_definition_cache 256
465a461
> stored_program_definition_cache 256
468d463
< sync_frm ON
475a471
> tablespace_definition_cache 256
Some interesting config differences between MariaDB 10.1 and MariaDB 10.2: some extra features integrated/gone compatible from the xtradb engine and more recent versions of MySQL; enabling the buffer pool dump by default, also setting Barracuda as the default file format, sql strict mode, new checksum algorithms, deleting deprecated variables, option for CTEs, and server_id now defaults to 1.
Nothing surprising here, for MySQL, the 5.7 regression still shows, now only around 10%; not sure if because of the work done already to mitigate it on BUG#75981, or just the different hardware I used compared to my last test. The good news is that the regressions seems solved for 8.0, getting even better results than 5.6. We will see if that maintains when we normalize the configuration options.
Regarding MariaDB, 10.0 shows a similar performance to 5.6 (probably within the range of potential measurement errors). What it is noticeable is a very small degradation for 10.1 and 10.2. Nothing that worries me, normally more features create a small overhead (the same has happened in MySQL in the past) which is in most cases worth paying, and many times not even noticeable under normal load. There is also still time for 10.2 to optimize potential problems.
WMF-like config
Let’s get a bit more serious, let’s test a configuration used in real life an let’s uniformize configurations. Wikimedia core production databases use this configuration. There are several things, however, I have to comment that will affect this test:
The tests here were not done on the same production machines, and some of the configuration has been heavily tuned for large amounts of memory available and hardware RAID controller, not available for the test
Some of the configuration options are MariaDB 10-dependent, with our build. They do not work on MySQL, or other versions of MariaDB- in those cases those options were disabled. Some of them work and were kept, but they may have a negative impact in this context.
It is obvioulsy not optimized for the specific LOAD DATA use case
WMF configuration is MariaDB 10-focused, so I expect MySQL server to not be properly tuned for it.
SSL was not used, probably not interesting for a single connection
Binary collation is used, as I commented before, it is the chosen charset/collation for mediawiki in WMF servers. As 8.0.0-dmr had the bug I mentioned not allowing that collation, I had to use the default collation there. Beware, that could skew its results
Buffer pool increased to 12GB, so that the whole file can fit into memory
Log file size increased to 2GB, so also that the whole file can fit into the transaction log
Performance schema enabled by default, this is very important for our query monitoring
No pool of connections (not available on MySQL)
Very large open_file_limits and max_connections, which requires downsizing the P_S parameters. (Update: I am being told that this is not necessary on 5.7 and 8.0, as it auto-resizes. I still tune it as I have to do it for MariaDB 10.0)
These are the results:
5.6.34
5.7.16
8.0.0-dmr
10.0.28
10.1.18
10.2.2
avg (seconds)
212.501
234.3543333
220.1906667 (*)
185.5396667
187.598
210.6946667
median (seconds)
212.48
234.608
220.123 (*)
188.16
191.393
209.287
rows inserted/s
219957.2049
199446.391
212275.6914 (*)
251919.8554
249155.7799
221842.9481
insert throughput compared to 5.6
100.00%
90.68%
96.51% (*)
114.53%
113.27%
100.86%
(*) Using UTF-8 collation because an 8.0.0 bug, which may impact the results
Again, if you prefer some graph bars:
The main conclusions that I can get from here is that my current performance configuration is not MySQL or MariaDB 10.2-ready. While in the case of 10.0 and 10.1, the performance has gotten around 11% better, for MariaDB 10.2 and MySQL, it has gotten worse, not better.
One thing that is not on the above summary is that MariaDB’s results, unlike MySQLs, even if better on average, have a higher amount of execution time variability. All test done on the 3 MySQL versions ended up within a second from each other. MariaDB results end up in a 10-second range. Throughput is not the only variable to take into account when doing performance testing: stability of timings could be important in many cases to provide a stable response time.
The other thing to comment, do these results show a more important regression for 10.2? Let’s do another test to confirm it.
Insecure config
Let’s try to test a configuration that optimizes for LOAD DATA speed, without regards for security (disabling features that you normally wouldn’t want to do in production: double write buffer, innodb checksums, …
The trend is similar to the previous results, with a 20-25% improvement in performance compared to the last test case. Except one version-8.0 seems to perform worse than on the previous configuration. This doesn’t make sense to me, but the results, like in the previous case, are consistent and repeatable. Is there a regression hidden here?
Regarding MariaDB, this configuration seems more stable (load-wise) for it, with less variability between runs. Still a downwards trend for newer versions.
One more result -SELECT count(*)
While checking that all the records were being inserted correctly, and no rows were lost in the process, I run into a curious case of different count + full scan speeds. When doing:
SELECT count(*) FROM nodes;
I got the following timings on console:
5.6.34
5.7.16
8.0.0-dmr
10.0.28
10.1.18
10.2.2
run time (seconds)
8.31 sec
4.81 sec
5.02 sec
1 min 47.88 sec
2 min 5.08 sec
6.61 sec
For those still obsessed on getting a nice bar chart every time:
I knew there were some optimizations on SELECT count(*) that made that faster for InnoDB (not instant, like MyISAM), but I didn’t know it was enabled as early as 5.6. It seems MariaDB only merged that feature (or a similar one doing the same) starting with 10.2.
Conclusions
Providing data without an explanation is a bad practice, however, I believe this will help as a starting point to debug (by me, or any others that would want to reproduce the results- I think I have given enough information to do that) and see what code points are blocking this memory-only, 1-thread concurrency specific test. Again, remember this is a very specific test and not a proper benchmark to base decisions on. The intended goals which were: 1) identify regressions 2) identify bugs 3) get a first quick look at the options changed and 4) start working with the newest versions, all were accomplished.
As a followup, I would like to explore more in depth those potentially observed regressions on 8.0 and 10.2, and see if it is just a case of adapting the configuration or if there is an underlying cause slowing them down. If they happened to be bugs, there should be plenty of time to fix those before a stable release from both vendors. The other thing that I would like to analyze next is this very same load type, but with innodb compression, and compare both the performance and the resulting file sizes.
I hope this has been helpful for someone else other than me, too. I have probably made some mistakes along the way, please tell me so on a comment or @jynus.
Last week, 21-23 September, it took place the European MySQL Conference, or “Data performance Conference” as this year’s subtitle was “MySQL. NoSQL. Data in the cloud.”. This year, it changed its location from London to Amsterdam and, as most people I talked to agreed, the change was for good. As every year, Percona was the company organizing it, but it had the participation of all the major players in the open source MySQL/MongoDB/Cloud data world. Special mention goes to Booking.com, which had more talks than usual (despite being one of the largest MySQL users out there), and were the hosts of the community diner (and probably one of the main reasons to moving to Amsterdam, as their main HQ is at that city).
While MySQL was still the king in terms of interest, I saw a growing interest for MongoDB, both from Percona (now owning TokuDB, and releasing its own Percona Server version of Mongo) and from Facebook, promoting its project RocksDB (its much improved fork of LevelDB, with both Mongo and MySQL frontends). Both are interesting offerings for write-heavy workloads with better compression ratios than other engines, but lacking of some features to be ready for everybody’s production usage. However, I have high expectations from both projects.
In a more personal way, for me it was great to devirtualize some people for the first time, plus get to catch up with others I already knew about both professionaly and personally. I had the chance to talk to people from all the previously mentioned companies (Percona, Facebook/RocksDB, Booking, Oracle) and also representatives, developers and DBAs from Google, Vividcortex, Solarwind, MariaDB, VMWare, Galera, Pythian, Github, Freelancers and more.
The “Concurso Universitario de Software Libre” (CUSL, Free Software University Contest), is an initiative similar to the Google Summer of Code, but specifically aimed to the Spanish university and high school students and organized by a group of Free Software University Offices.
The final phase of the competition will take place on the 7-8 May in Zaragoza, and our MySQL consultant Jaime Crespo will deliver on that Friday a short speech in Spanish titled “Free Software ¿Is it profitable?”.
Mermaids have the same probability of fixing your permission problems, but people continue believing in the FLUSH PRIVILEGES myth.
I see suggesting the usage of FLUSH PRIVILEGES every time someone writes a tutorial or a solution to a problem regarding creating a new account or providing different privileges. For example, the top post on /r/mysql as of the writing of these lines, “MySQL:The user specified as a definer does not exist (error 1449)-Solutions” has multiple guilty cases of this (Update: the user has corrected those lines after I posted this article).
It is not my intention to bash that post, but I have seen committing that mistake many, many times. Even if you go to the reference manual for the GRANT command, you will see a comment at the bottom -from a third party user- using GRANT and then FLUSH PRIVILEGES.
Why should I bother? Is executing FLUSH PRIVILEGES an issue? Why is everybody doing it? The reason why that command exists is because —in order to improve performance— MySQL maintains an in-memory copy of the GRANT tables, so it does not require to read it from disk on every connection, every default database change and every query sent to the server. The mentioned command forces the reload of this cache by reading it directly from disk (or the filesystem cache) as the MySQL reference manual itself clearly indicates (having even its own section: When Privilege Changes Take Effect). However, its execution is unnecessary in most practical cases because:
If you modify the grant tables indirectly using account-management statements such as GRANT, REVOKE, SET PASSWORD, or RENAME USER, the server notices these changes and loads the grant tables into memory again immediately.
Then only reason to perform that reload operation manually is when:
you modify the grant tables directly using statements such as INSERT, UPDATE, or DELETE
For most operations, like creating a user, changing its privileges, or changing its password, you will want to use the high-level statements. Not only they are easier to use and they are compatible with a larger number of MySQL versions, but they will also prevent you from making mistakes (of course, remember to setup the “NO_AUTO_CREATE_USER“ sql mode). They even usually work nicely in a MyISAM-hostile environment like a Galera cluster. There are certainly reasons to edit the tables manually- as an administrator, you may want to tweak the privileges in a special way or import the mysql.* tables from elsewhere, so in those cases running FLUSH PRIVILEGES is mandatory. Please note that, as the manual page says, in most cases (e.g. global privileges) changing a user’s grants will only affect new connections, and certainly never to ongoing queries, as privileges are checked at the beginning of the query processing- read the manual page for details.
So, again, why my crusade against the overuse of FLUSH PRIVILEGES, after all, worst case scenario, the same privileges will be loaded again! It is not a question of performance issues. Although, in an extreme case it certainly can be an issue. Check for example the following script, that executes 10 000 CREATE USER statements (this can only be done in a single thread as the grant tables are still in MyISAM format, even in 5.7.6):
def execute_test(port, drop, flush, thread):
db = mysql.connector.connect(host="localhost", port=port, user="msandbox", passwd="msandbox", database="test")
for i in range(0, TIMES):
cursor = db.cursor()
if (drop):
sql = "DROP USER 'test-" + `thread` + '-' + `i` + "'@'localhost'"
else:
sql = "CREATE USER 'test-" + `thread` + '-' + `i` + "'@'localhost' IDENTIFIED BY '" + DEFAULT_PASSWORD + "'"
cursor.execute(sql)
cursor.close()
db.commit()
if (flush):
cursor = db.cursor()
flush_sql = "FLUSH PRIVILEGES"
cursor.execute(flush_sql)
cursor.close()
db.commit()
db.close()
The timing for both executions are:
$ time ./test_flush.py
Not flushing
Executing the command 10000 times
real 0m15.508s
user 0m0.827s
sys 0m0.323s
$ ./test_flush.py -d
Not flushing
Dropping users
Executing the command 10000 times
$ time ./test_flush.py -f
Flushing after each create
Executing the command 10000 times
real 2m7.041s
user 0m2.482s
sys 0m0.771s
$ ./test_flush.py -d
Not flushing
Dropping users
Executing the command 10000 times
We can see that using FLUSH PRIVILEGES is 8x slower that not using them. Again, I want to stress that performance is not the main issue here, as most people would execute it only once at the end of each command block, so it wouldn’t be a huge overload. Even if there is some extra read IO load, we must assume that every round trip to the database, and every commit takes some server resources -so that can be extrapolated to any command. Additionally, concurrency issues is not a typical problem for MySQL account creation, as the mysql.user table it not usually (or should not be) very dynamic.
The main issue I have against the overuse of FLUSH PRIVILEGES is that people execute it without really understanding why they do it and what that command actually does. Every time a person has a problem with MySQL privilege systems, the first piece of advice that is given is to execute this command “just in case”. Check, for example, answers on dba.stackexchange like this, this and this (which I have selected among many others), and where the original user was not altering manually the mysql.* tables. The issue is that in most cases this command does nothing, and the real problem lays on the poor understanding of MySQL’s permission model. As the saying tells- when you have a hammer, every problem looks like a nail. People read that that is a proper way to solve permission-related problems, and they pass the “knowledge” on, creating basically the MySQL equivalent of an urban myth.
So, the next time you encounter a problem with a user not being able to log it, or apply privileges to a user, there are many other sources of issues such as: using old_passwords, using a different authentication method than the native passwords, not having the actual privileges or the WITH GRANT OPTION properties to apply them, your server not identifying you with the same user or host than the one you are actually in, using skip-name-resolve so dns entries are ignored, waiting for a new connection for the changes to take effect, … and many other issues that come with authorization and authentication. MySQL grant system is not precisely obvious and perfect (Hello, granting permissions from databases that do not exist?), but taking 5 minutes to read the extensive manual on privileges can avoid you many headaches in the future. TL;TR RTFM
For those people that already know when to use or not to use FLUSH PRIVILEGES, please, next time you find someone overusing it, educate the user on best practices so people no longer relay in magic and urban myths to solve problems, go to reddit/stackoverflow/your favorite social network/etc. and upvote good practices/comment on bad practices. Today it could be FLUSH PRIVILEGES, tomorrow it could be “add OPTIMIZE TABLE in a cron job every 5 minutes for your InnoDB tables” (and yes, that last one was actually found in the wild).
While we always want better performance and more and larger features for MySQL, those cannot just “magically appear” from one version to another, requiring deep architecture changes and lots of lines of code. However, there are sometimes smaller features and fixes that could be implemented by an intern or an external contributor, mainly at SQL layer, and that could make the MySQL ecosystem friendlier to newbies and non-experts. Making a piece of software easier to use is sometimes overlooked, but it is incredibly important -not everybody using MySQL is a DBA, and the more people adopting it, more people will be able to live from it, both upstream and as third party providers.
Here it is my own personal list of fixes for EXPLAIN messages. If you are an experienced MySQL user you are probably aware of their meaning, but that doesn’t solve the problem for beginners. The reason why I am writing a blog post is to gather opinions on whether they seem important to you or not, and if my way of solving them seems reasonable so that we can submit them as feature requests.
EXPLAIN messages
As a MySQL instructor, the following case happens a lot with new students. You start with a command like this:
mysql> EXPLAIN SELECT b, c FROM test\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test
type: index
possible_keys: NULL
key: b_c
key_len: 10
ref: NULL
rows: 4
Extra: Using index
1 row in set (0.00 sec)
So, “Using index” means that an index is being used, right? No, in this case, the type: index is telling us that it is using an index for scanning or accessing the rows (because it is not a type: ALL– although we could get a full row scan and using the index for ordering or grouping them). The Extra: Using index indicates that the index is also used for retrieving the data, without actually needing to read the whole row. This is, as far as I know, commonly referred as Covering index. And that is exactly what I would like to see:
mysql> EXPLAIN SELECT b, c FROM test\G -- edited output
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test
type: index
possible_keys: NULL
key: b_c
key_len: 10
ref: NULL
rows: 4
Extra: Using covering index
1 row in set (0.00 sec)
or maybe:
Extra: Covering index
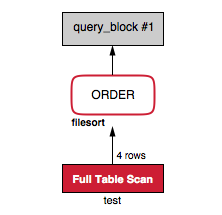
Another common misunderstanding: Using filesort:
mysql> EXPLAIN SELECT * FROM test ORDER BY length(b)\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 4
Extra: Using filesort
1 row in set (0.00 sec)
At this level, I do not care if I am using filesort as an algorithm, and -if I am correct- since 5.6 can also use a priority queue for the sorting algorithm if the number of items is small. Additionally, the “file” in the filesort word can lead to confusion that this requires a temporary table on disk. I do not have a perfect alternative (please provide feedback), but maybe something like the following would be clearer:
mysql> EXPLAIN SELECT * FROM test ORDER BY length(b)\G -- edited output
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 4
Extra: Additional sort phase
1 row in set (0.00 sec)
or maybe:
Extra: Not using index for order-by
Another example would be:
mysql> EXPLAIN SELECT a FROM test WHERE b > 3 and c = 3\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test
type: range
possible_keys: b_c
key: b_c
key_len: 5
ref: NULL
rows: 1
Extra: Using index condition
1 row in set (0.00 sec)
I understand that the developers didn’t want to confuse us with NDB’s pushed condition, but this output is quite misleading, too. It literally means that “the index condition is being used”, instead of “ICP is being used”. What about:
mysql> EXPLAIN SELECT a FROM test WHERE b > 3 and c = 3\G -- edited output
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test
type: range
possible_keys: b_c
key: b_c
key_len: 5
ref: NULL
rows: 1
Extra: Using index condition pushdown
1 row in set (0.00 sec)
There are many other expressions, but those are the most annoying to me in terms of students’ confusion.
Would you agree with me? Would these changes break applications that may parse EXPLAIN output? What other small things would you change in MySQL output or error messages? I would specially would like to hear from MySQL beginners and people coming from other databases, as the more we have used to it, the more we get accustomed to MySQLisms.
However, I have seen many people assuming that because default_tmp_storage_engine has the value “InnoDB”, all temporary tables are created in InnoDB format in 5.6. This is not true: first, because implicit temporary tables are still being created in memory using the MEMORY engine (sometimes called the HEAP engine), while MyISAM is being used for on-disk tables. If you do not trust the reference manual on this, here it is a quick test to check it:
mysql> SELECT version(); +------------+ | version() | +------------+ | 5.6.23-log | +------------+ 1 row in set (0.00 sec)
mysql> SHOW GLOBAL VARIABLES like 'default%'; +----------------------------+--------+ | Variable_name | Value | +----------------------------+--------+ | default_storage_engine | InnoDB | | default_tmp_storage_engine | InnoDB | | default_week_format | 0 | +----------------------------+--------+ 3 rows in set (0.00 sec)
mysql> SHOW GLOBAL VARIABLES like 'tmpdir'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | tmpdir | /tmp | +---------------+-------+ 1 row in set (0.00 sec)
mysql> CREATE TABLE test (id serial, a text); Query OK, 0 rows affected (0.10 sec)
mysql> insert into test (a) values ('a'); Query OK, 1 row affected (0.06 sec)
mysql> insert into test (a) values ('aa'); Query OK, 1 row affected (0.00 sec)
mysql> insert into test (a) values ('aaa'); Query OK, 1 row affected (0.00 sec)
mysql> SELECT *, sleep(10) FROM test ORDER BY rand(); ...
[ec2-user@jynus_com tmp]$ ls -la total 24 drwxrwxrwt 5 root root 4096 Feb 24 11:55 . dr-xr-xr-x 23 root root 4096 Jan 28 14:09 .. drwxrwxrwt 2 root root 4096 Jan 28 14:09 .ICE-unix -rw-rw---- 1 mysql mysql 0 Feb 24 11:55 #sql_7bbd_0.MYD -rw-rw---- 1 mysql mysql 1024 Feb 24 11:55 #sql_7bbd_0.MYI drwx------ 2 ec2-user ec2-user 4096 Feb 24 11:41 ssh-5ZGoXWFwtQ drwx------ 2 ec2-user ec2-user 4096 Feb 24 11:43 ssh-w9IkW0SvYo
... +----+------+-----------+ | id | a | sleep(10) | +----+------+-----------+ | 1 | a | 0 | | 2 | aa | 0 | | 3 | aaa | 0 | +----+------+-----------+ 3 rows in set (30.00 sec)
The only thing I have done above is forcing the creation of the temporary table on disk by adding a TEXT field (incompatible with the MEMORY engine, so it has to be created on disk) and using sleep so that we have enough time to check the filesystem. You can see on the output of ls the .MYD and .MYI particular to the MyISAM engine. That last step would be unnecessary if we just used PERFORMANCE_SCHEMA to check the waits/io.
A second, and more obvious reason why thinking that all temporary tables are created in InnoDB format, is because explicit temporary tables can still be created in a different engine with the ENGINE keyword:
mysql> CREATE TEMPORARY TABLE test (i serial) ENGINE=MyISAM; Query OK, 0 rows affected (0.00 sec)
[ec2-user@jynus_com tmp]$ ls -la total 36 drwxrwxrwt 5 root root 4096 Feb 24 12:16 . dr-xr-xr-x 23 root root 4096 Jan 28 14:09 .. drwxrwxrwt 2 root root 4096 Jan 28 14:09 .ICE-unix -rw-rw---- 1 mysql mysql 8554 Feb 24 12:12 #sql7bbd_36a3_0.frm -rw-rw---- 1 mysql mysql 0 Feb 24 12:12 #sql7bbd_36a3_0.MYD -rw-rw---- 1 mysql mysql 1024 Feb 24 12:12 #sql7bbd_36a3_0.MYI drwx------ 2 ec2-user ec2-user 4096 Feb 24 11:41 ssh-5ZGoXWFwtQ drwx------ 2 ec2-user ec2-user 4096 Feb 24 11:43 ssh-w9IkW0SvYo
[ec2-user@jynus_com tmp]$ ls -la total 20 drwxrwxrwt 5 root root 4096 Feb 24 12:17 . dr-xr-xr-x 23 root root 4096 Jan 28 14:09 .. drwxrwxrwt 2 root root 4096 Jan 28 14:09 .ICE-unix drwx------ 2 ec2-user ec2-user 4096 Feb 24 11:41 ssh-5ZGoXWFwtQ drwx------ 2 ec2-user ec2-user 4096 Feb 24 11:43 ssh-w9IkW0SvYo
Will this change in the future? 5.7.5 continues to have the same behavior as 5.6. However, as Stewart pointed some time ago, the performance optimizations in 5.7 make some uses of MEMORY and MyISAM obsolete so I will not be surprised if that dependency, together with MyISAM grant tables, will be removed in the future.
Update: I’ve been told by email by Morgan that the yet-to-be-released (at the time of this writing) 5.7.6 will finally change the default behavior to be full InnoDB for implicit temporary tables, too, as seen on the release notes:
InnoDB: The default setting for the internal_tmp_disk_storage_engine option, which defines the storage engine the server uses for on-disk internal temporary tables (see How MySQL Uses Internal Temporary Tables), is now INNODB. With this change, the Optimizer uses the InnoDB storage engine instead of MyISAM for internal temporary tables.
internal_tmp_disk_storage_engine was introduced in 5.7.5, but its default value then was MYISAM.
This is in order to get advantage of the in-memory performance of InnoDB for variable-lengh fields, which I am personally 100% for. Thank you Morgan for the extra information!















{kind=link}