
Como mencioné en mi anterior entrada, donde comparaba las opciones de configuración por defecto de 5.6 y 5.7, he estado haciendo algunos tests para un tipo particular de carga en varias versiones de MySQL. Lo que he estado comprobando es las diferentes maneras de cargar un archivo CSV (el mismo fichero que usé para comprobar las herramientas de compresión) en MySQL. Aquellos administradores de bases de datos y programadores MySQL con experiencia probablemente ya conozcáis la respuesta, así que podéis saltar a los resultados de 5.7 respecto de 5.6. Sin embargo, la primera parte de este post está dedicado a los desarrolladores/aquellos que dan sus primeros pasos con MySQL que desean saber la respesta a la pregunta del título, paso a paso. Debo decir que yo también he aprendido algo, ya que sobrestimé e infravaloré algunos efectos de ciertas opciones de configuración para este tipo de carga.
Aviso: no pretendo realizar benchmarks formales, la mayoría de los resultados obtenidos aquí se han creado ejecutándose un par de veces, y muchos de ellos con la configuración por defecto. Esto ha sido por diseño, ya que intento mostrar alguna de las “malas prácticas” para la gente que acaba de empezar a trabajar con MySQL, y lo que deberían evitar hacer. Tan sólo la comparativa entre 5.6 y 5.7 me ha llamado la antención. Aviso adicional: No me llamo a mí mismo programador, y mucho menos un programador de Python, así que me disculpo por adelantado por mi código- después de todo, esto va de MySQL. El enlace de descarga de los scripts está al final del post.
Las reglas
Empiezo con un archivo CSV (recordad que realmente es un archivo de valores separado por comas, TSV) que tiene 3.700.635.579 bytes de tamaño, y 46.741.126 filas y tiene la siguiente pinta:
171773 38.6048402 -0.0489871 4 2012-08-25 00:37:46 12850816 472193 rubensd 171774 38.6061981 -0.0496867 2 2008-01-19 10:23:21 666916 9250 j3m 171775 38.6067166 -0.0498342 2 2008-01-19 10:23:21 666916 9250 j3m 171776 38.6028122 -0.0497136 5 2012-08-25 00:26:40 12850816 472193 rubensd 171933 40.4200658 -3.7016652 6 2011-11-29 05:37:42 9984625 33103 sergionaranja
Quiero cargarlo en la siguiente tabla, con la estructura que muestro a continuación:
CREATE TABLE `nodes` (
`id` bigint PRIMARY KEY,
`lat` decimal(9,7),
`lon` decimal(10,7),
`version` int,
`timestamp` timestamp,
`changeset` bigint,
`uid` bigint,
`user` varchar(255)
);
El tiempo de importación termina en el momento que la tabla es crash safe (resistente a fallos) (aunque quede E/S pendiente). Eso quiere decir que para InnoDB, el último COMMIT realizado tiene que haberse hecho de manera satisfactoria y flush_log_at_trx_commit debe valer 1, de manera que aunque queden operaciones de escritura por hacerse, es completamente consistente con disco. Para MyISAM, eso quiere decir que fuerzo la ejecución de un FLUSH TABLES antes de terminar el test. Estos, por supuesto, no son equivalentes, pero al menos es una manera de asegurarse de que todo está más o menos sincronizado con disco. Ésta es la parte final de todos mis scripts:
# finishing
if (options.engine == 'MyISAM'):
cursor.execute('FLUSH TABLES')
else:
db.commit()
cursor.close()
db.close()
Para el hardware y sistema operativo, comprobad los detalles de máquina de este post antiguo– usé el mismo entorno que el mencionado aquí, con la excepción de usar CentOS7 en vez de 6.5.
Empezando con un método muy ingenuo
Digamos que soy un desarrollador al que le han asignado cargar de manera regular un archivo en MySQL, ¿cómo lo haría? Probablemente estaría tentado de usar una biblioteca de parseo de CSV, el conector de MySQL, y los uniría a ambos juntos en un bucle. ¿Eso funcionaría, no? La parte principal del código sería algo como esto (load_data_01.py):
# import
insert_node = "INSERT INTO nodes (id, lat, lon, version, timestamp, changeset, uid, user) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)"
with open(CSV_FILE, 'rb') as csv_file:
csv_reader = csv.reader(csv_file, delimiter='\t')
for node in csv_reader:
cursor.execute(insert_node, node)
Como estoy interpretando el papel de un desarrollador sin experiencia, también usaría la configuración por defecto. Veamos qué resultados obtenemos (de nuevo, esta es la razón por la cual llamo a esto “pruebas”, y no benchmarks). Menos es mejor:
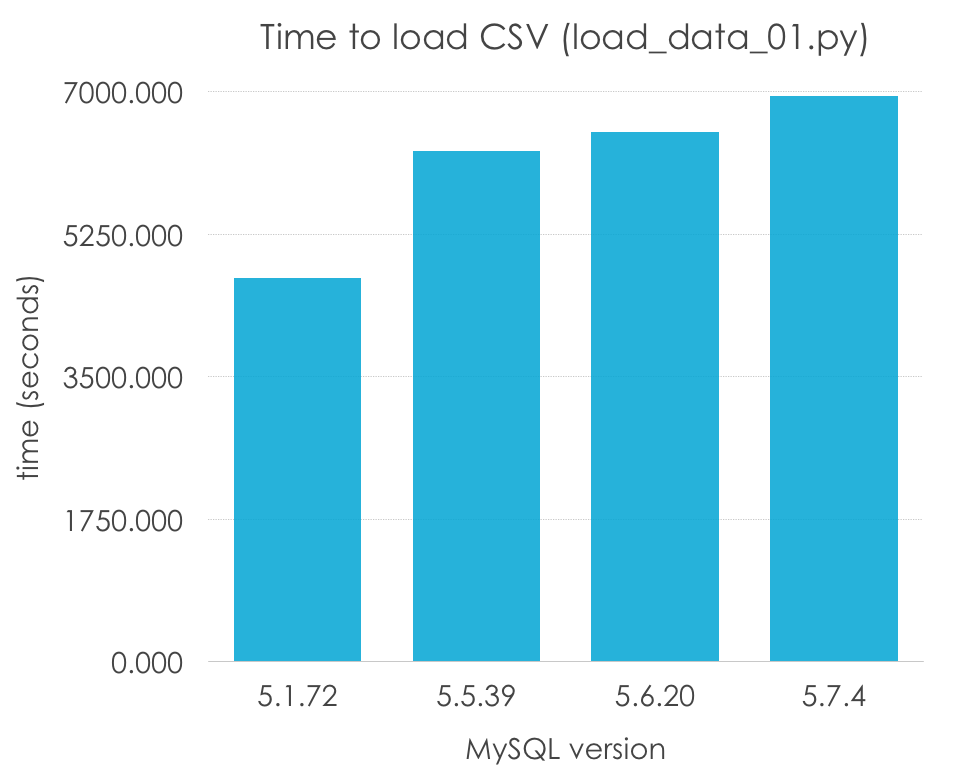
| MySQL Version | 5.1.72 | 5.5.39 | 5.6.20 | 5.7.4 |
| Load time (seconds) | 4708.594 | 6274.304 | 6499.033 | 6939.722 |
Guau, ¿5.1 es un 50% más rápido que el resto de versiones? Incorrecto, recordad que 5.5 fue la primera versión en introducir InnoDB como el motor por defecto, e InnoDB tiene una sobrecarga debido a las transacciones, y normalmente no tiene una muy buena configuración por defecto (al contrario que MyISAM, que estan simple que las opciones por defecto pueden funcionar en muchos casos). Normalicemos los resultados por motor de almacenamiento:
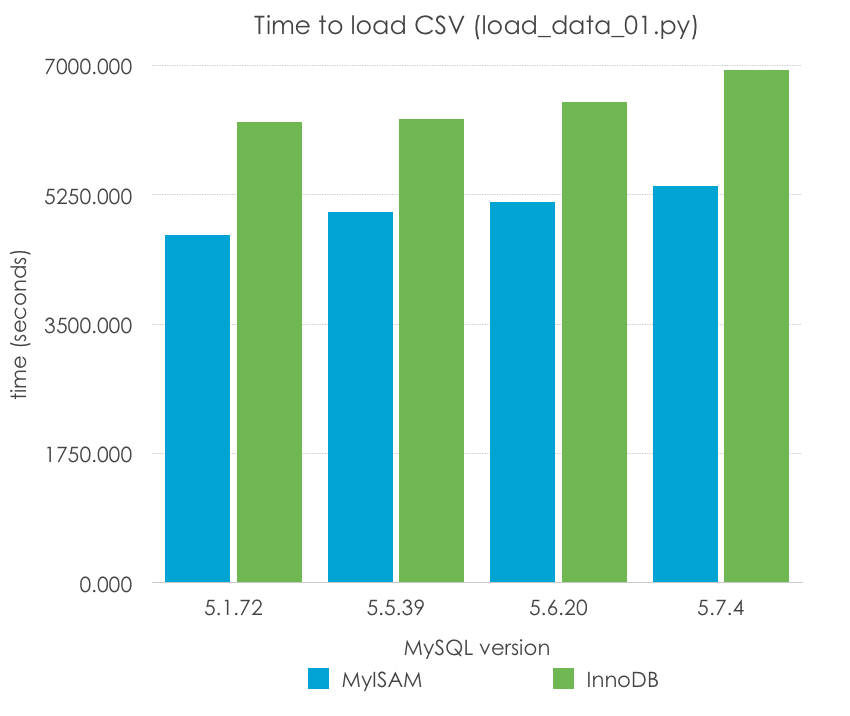
| MySQL Version | 5.1.72 | 5.5.39 | 5.6.20 | 5.7.4 |
| MyISAM | 4708.594 | 5010.655 | 5149.791 | 5365.005 |
| InnoDB | 6238.503 | 6274.304 | 6499.033 | 6939.722 |
Esto ya parece más razonable, ¿no? Sin embargo, en este caso, parece haber una ligero empeoramiento en el rendimiento de un sólo hilo a la vez que las versiones van progresando, especialemnte en MySQL 5.7. Por supuesto, es pronto para sacar conclusiones, porque este método de carga de un archivo CSV, fila a fila, es uno de los más lentos, y además estamos usando unas opciones de configuración muy pobres (las que vienen por defecto) -las cuales varían de versión a versión- y que no deberían usarse para llegar a ninguna conclusión.
Lo que podemos decir es que MyISAM parece funcionar mejor para este escenario muy específico por las razones que comentaba antes, pero aún así tardaríamos de 1 a 2 horas en cargar un archivo tan sencillo.
Otro método incluso más ingenuo
La siguiente pregunta no es: ¿podemos hacerlo mejor? sino ¿podemos hacerlo incluso más lento? Un texto en particular me llamó la atención mientras miraba la documentación del conector de MySQL:
Since by default Connector/Python does not autocommit, it is important to call this method after every transaction that modifies data for tables that use transactional storage engines.
que es algo así como:
Debido a que por defecto Connector/Python no realiza autocommit, es importante llamar a este método después de cualquier transacción que modifique datos en tablas de motores transaccionales.
-de la documentación de connector/python
Pensé- ¡ah!, entonces podemos reducir el tiempo de importación realizando commit para cada fila de la base de datos, una a una, ¿no? Después de todo, estamos insertando en la tabla en una única transacción enorme. ¡Seguro que crear un enorme número de transacciones será mejor! 🙂 Este es el código ligeramente modificado (load_data_02.py):
insert_node = "INSERT INTO nodes (id, lat, lon, version, timestamp, changeset, uid, user) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)"
with open('/tmp/nodes.csv', 'rb') as csv_file:
csv_reader = csv.reader(csv_file, delimiter='\t')
for node in csv_reader:
cursor.execute(insert_node, node)
db.commit()
Y en este caso no tengo ni siquiera un bonito gráfico que enseñaros, porque después de 2 horas, 19 minutos y 39.405 segundos, cancelé la importación porque sólo se habían insertado 111533 nodos en MySQL 5.1.72 con InnoDB con la configuración por defecto (innodb_flush_log_at_trx_commit = 1). Obviamente, millones de fsyincs no harán que la carga sea más rápida, considerad esto como una lección aprendida.
Haciendo progresos: multi-inserts
El siguiente paso que quería probar es cómo de efectivo es agrupar consultas en inserciones múltiples. Este método lo usa mysqldump, y supuesta mente minimiza la carga extra de SQL por tener que gestionar cada consulta por separado (parseo, comprobación de permisos, plan de la consulta, etc.). Éste es el código principal (load_data_03.py):
concurrent_insertions = 100
[...]
with open(CSV_FILE, 'rb') as csv_file:
csv_reader = csv.reader(csv_file, delimiter='\t')
i = 0
node_list = []
for node in csv_reader:
i += 1
node_list += node
if (i == concurrent_insertions):
cursor.execute(insert_node, node_list)
i = 0
node_list = []
csv_file.close()
# insert the reminder nodes
if i > 0:
insert_node = "INSERT INTO nodes (id, lat, lon, version, timestamp, changeset, uid, user) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)"
for j in xrange(i - 1):
insert_node += ', (%s, %s, %s, %s, %s, %s, %s, %s)'
cursor.execute(insert_node, node_list)
Lo probamos con, por ejemplo, 100 filas insertadas en cada consulta. ¿Cuáles son los resultados? Menos es mejor:
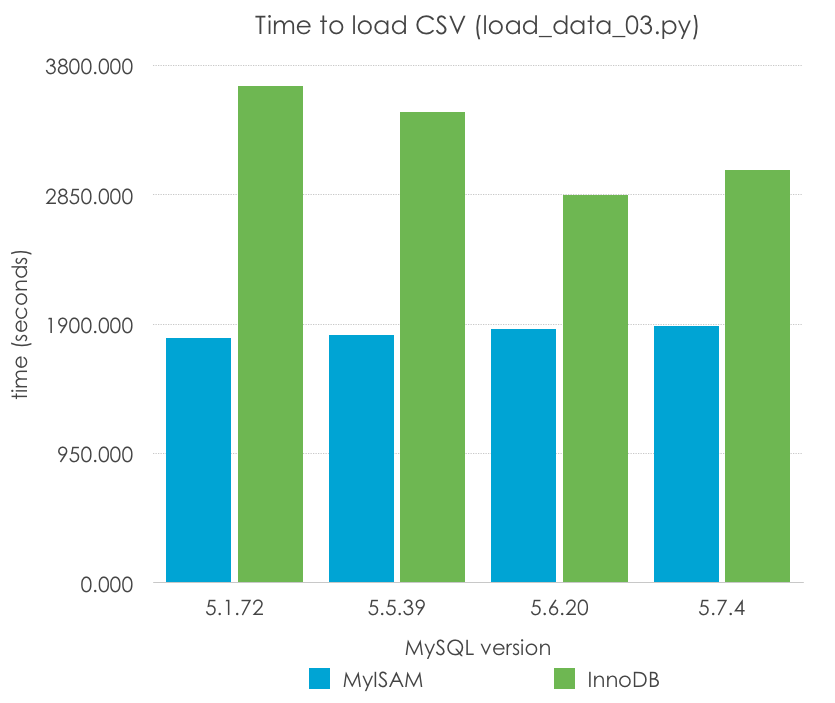
| MySQL Version | 5.1.72 | 5.5.39 | 5.6.20 | 5.7.4 |
| MyISAM | 1794.693 | 1822.081 | 1861.341 | 1888.283 |
| InnoDB | 3645.454 | 3455.800 | 2849.299 | 3032.496 |
Con este método observamos una mejora en el tiempo de importación de 262-284% respecto del tiempo original para MyISAM y de 171-229% respecto del tiempo original de InnoDB. Recordad que este método no escalará indefinidamente, ya que encontraremos un límite en el tamaño de paquete si intentamos insertar demasiadas filas a la vez. Sin embargo, se trata de una clara ventaja sobre el insertado fila a fila.
Los tiempos para MyISAM son esencialmente los mismos entre versiones, mientras que InnoDB muestra una mejora a lo largo del tiempo (que podrían deberse a los cambios en código y la optimización, pero también a la configuración por defecto del tamaño del log de transacciones), excepto de nuevo entre 5.6 y 5.7.
El método correcto para importar datos: Load Data
Si se tiene un mínimo de experiencia con MySQL, conoceréis la existencia de una palabra clave especializada para importaciones, y ésta es LOAD DATA. Veamos como quedaría el código usando esta opción (load_data_04.py):
# data import
load_data = "LOAD DATA INFILE '" + CSV_FILE + "' INTO TABLE nodes"
cursor.execute(load_data)
¿Simple, verdad? Con esto estamos minimizando la sobrecarga de SQL, y ejecutando el bucle en código C compilado de MySQL. Echemos un vistazo a los resultados (menos es mejor):
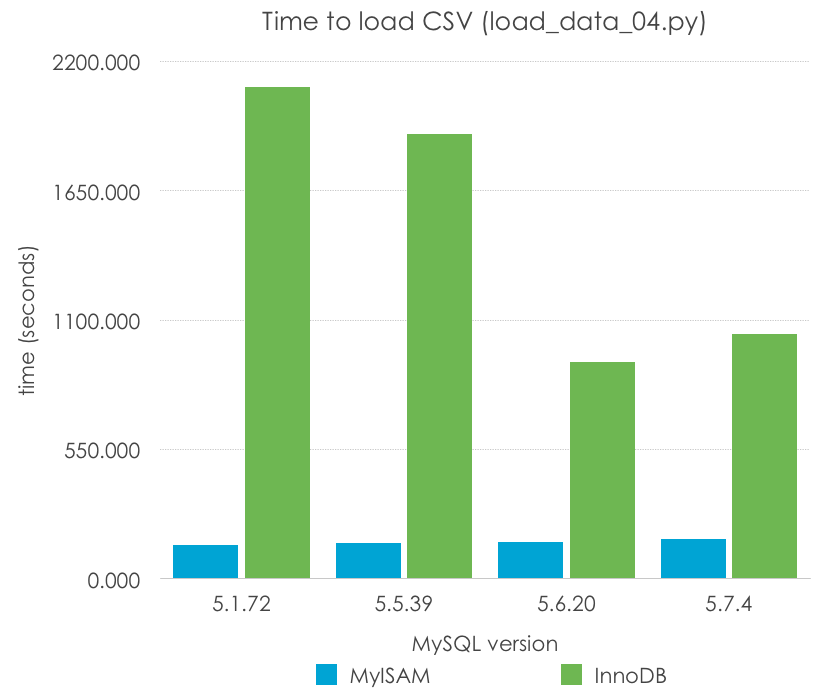
| MySQL Version | 5.1.72 | 5.5.39 | 5.6.20 | 5.7.4 |
| MyISAM | 141.414 | 149.612 | 155.181 | 166.836 |
| InnoDB | 2091.617 | 1890.972 | 920.615 | 1041.702 |
En este caso, MyISAM tiene una mejora dramática –LOAD DATA convierte la importación en 12 veces más rápida. InnoDB, de nuevo todavía con los parámetros por defecto mejora en 3 veces, y más significativamente en las versiones más recientes (5.6, 5.7) que en las anteriores (5.1, 5.5). Mi predicción es que esto tiene mucho más que ver con la diferente configuración de los archivos de log que con cambios en el código.
Intentado mejorar Load Data para MyISAM
¿Podemos mejorar los tiempos de carga para MyISAM? Hay dos cosas que podemos hacer -aumentar el tamaño de key_cache_size y deshabilitar Performance Schema para 5.6 y 5.7. Establecí el tamaño de la caché de índices (key_cache_size) en 600M (intentado que cupiera la clave primaria en memoria) y cambié performance_schema = 0, probando las 3 combinaciones restantes. Menos es mejor:
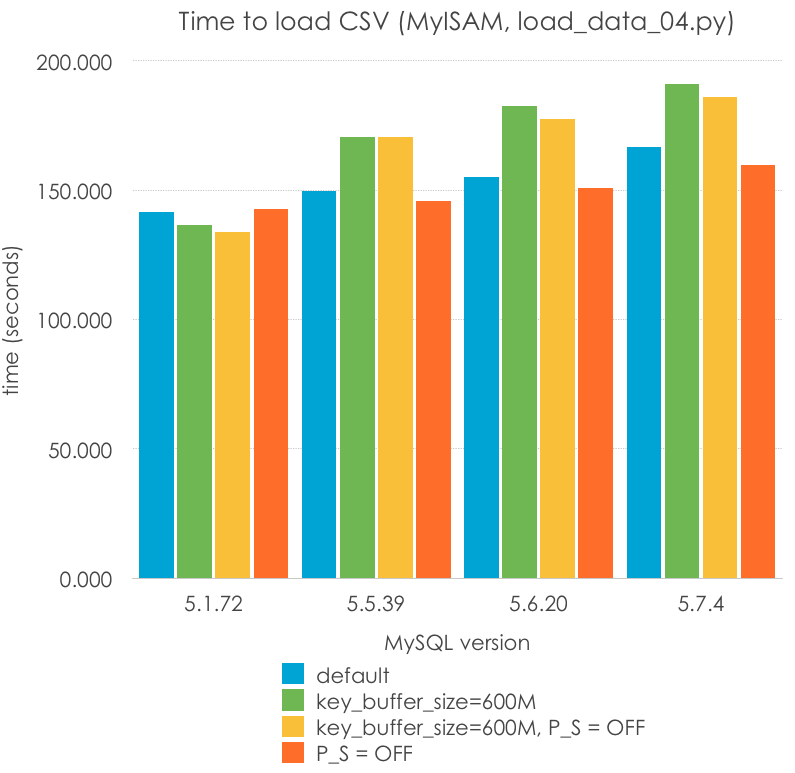
| MySQL Version | 5.1.72 | 5.5.39 | 5.6.20 | 5.7.4 |
| default | 141.414 | 149.612 | 155.181 | 166.836 |
| key_buffer_size=600M | 136.649 | 170.622 | 182.698 | 191.228 |
| key_buffer_size=600M, P_S = OFF | 133.967 | 170.677 | 177.724 | 186.171 |
| P_S = OFF | 142.592 | 145.679 | 150.684 | 159.702 |
Hay varias cosas que destacar aquí:
P_S=ONandP_S=OFFno debería tener un efecto en MySQL 5.1 y 5.5, pero se muestran resultados diferentes debido a errores de medida. De ahí podemos entender que sólo 2 cifras son realmente significativas.key_buffer_cache, en general, no mejora el rendimiento, de hecho se podría decir que estadísticamente la empeora. Esto es razonable porque, después de todo, estoy escribiendo a la caché de archivos, y una caché de claves mayor puede requerir una reserva o copia de memoria más costosa. Esto debería investigarse más a fondo para llegar a una conclusión.- Performance_schema podría estar empeorando el rendimiento de esta carga, pero no estoy seguro estadísticamente hablando.
- MyISAM (o quizás el servidor MySQL) parece haber empeorado su rendimiento para este tipo de carga (carga por lotes con un sólo hilo).
Hay más cosas que me gustaría probar con MyISAM, como ver el impacto de los diferentes formatos de fila (fixed) pero me gustaría continuar con los otros motores.
Intentado mejorar Load Data en InnoDB
InnoDB es un motor mucho más interesante, ya que es ACIDo por defecto, y más complejo. ¿Podemos hacerlo tan rápido como MyISAM para una importación?
La primera cosa que quiero cambiar son los valores por defecto de innodb_log_file_size y innodb_buffer_pool_size. El log es diferente antes y después de 5.6, y no es adecuado para una gran carga de escritura. Lo cambié para un primer test a 2G, que es el mayor tamaño que 5.1 y 5.5 pueden usar (lo puse a 2.147.483.136 ya que tiene que se menor de 2G), lo cual quiere decir que tenemos un tamaño total de los logs de 4G. También cambié el buffer pool a una tamaño más conveniente, 8GB, suficiente para albergar el tamaño completo del conjunto de datos. Recordad que una de las razones por las cuales InnoDB es tan lento a la hora de realizar importaciones es porque escribe las nuevas páginas (al menos) dos veces a disco -en el log, y en el espacio de tablas. Sin embargo, con estos parámetros, la segunda escritura debería realizarse en su mayoría a través del buffer de memoria. Estos son los nuevos resultados (menos es mejor):

| MySQL Version | 5.1.72 | 5.5.39 | 5.6.20 | 5.7.4 |
| default | 1923.751 | 1797.220 | 850.636 | 1008.349 |
| log_file_size=2G, buffer_pool=8G | 1044.923 | 1012.488 | 743.818 | 850.868 |
Ahora esto es un test que parece más razonable. Podemos comentar que:
- La mayoría de las mejoras que teníamos antes en 5.6 y 5.7 respecto a 5.1 y 5.5 se debían al tamaño de log 10 veces más grande.
- Aún así, 5.6 y 5.7 son más rápidos que 5.1 y 5.5 (algo razonable, ya que 5.6 ha visto unos cambios en InnoDB impresionantes, tanto en código como en configuración)
- InnoDB continúa siendo al menos 5 veces más lento que MyISAM
- ¡Y 5.7 continúa siendo más lento que 5.6! Estamos teniendo una regresión consistente de un 13-18% en 5.7 (y me estoy empezando, ahora sí, a preocupar)
Comenté antes que el mayor overhead de InnoDB es escribir los datos 2 veces (al log y a las tablas). Esto es en realidad incorrecto, ya que podría tener que escribirlos 3 veces (al área de doble escritura) e incluso 4, en el log binario. El log binario no está activo por defecto, pero el double write sí, ya que permite protegernos de la corrupción. Aunque nunca recomendamos deshabilitar esta estructura en producción, la verdad es que en una importación nos da igual si los datos terminan corruptos (ya que podríamos borrarlos y volver a reimportarlos). También hay opciones en algunos sistemas de archivos para evitar tener que activarlo.
Otras características que están en InnoDB por seguridad, no por rendimiento, son los checksums de InnoDB- éstos incluso se convierten en el cuello de botella en sistemas de almacenamiento utrarrápidos como tarjetas flash PCI. En estos casos, ¡la CPU es demasiado lenta para calcularlos! Sospecho que esto no será un problema en este caso porque las versiones más modernas de MySQL (5.6 y 5.7) tienen la opción de cambiarlo por la función acelerada por hardare CRC32 y, mayormente, porque estoy usando discos magnéticos, que son el verdadero cuello de botella aquí. Pero no nos fiemos de lo que hemos aprendido y pongámoslo a prueba.
La otra cosa que podemos comprobar es la sobrecarga de performance_schema. He encontrado casos en los que por el tipo de operaciones produce tiene un efecto negativo bastante notable, mientras que casi ninguno en otros. Probemos también a activarlo y deshabilitarlo.
Estos son los resultados (menos es mejor):
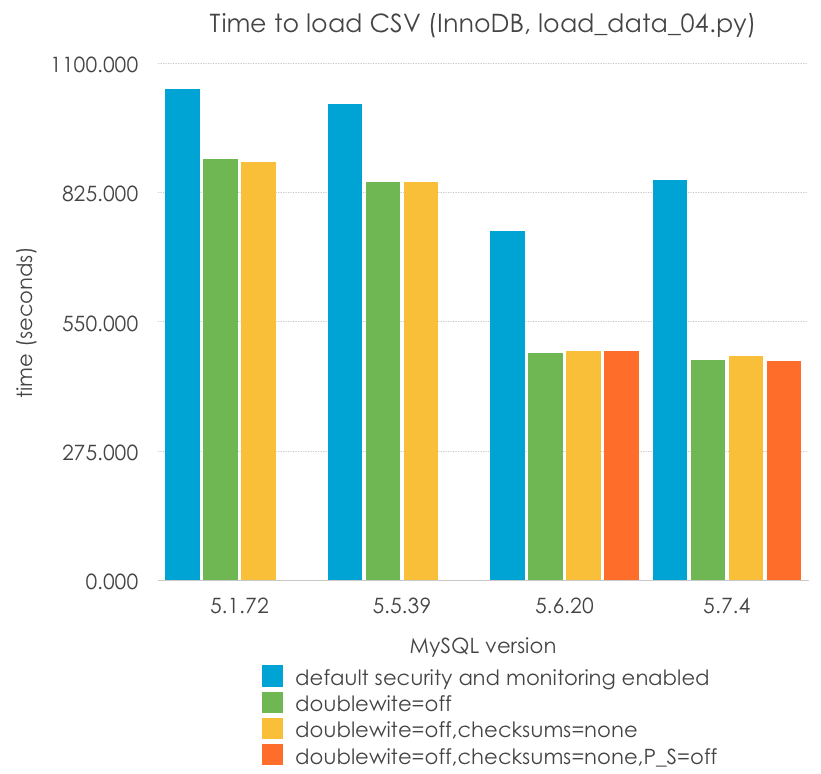
| MySQL Version | 5.1.72 | 5.5.39 | 5.6.20 | 5.7.4 |
| default security and monitoring enabled | 1044.923 | 1012.488 | 743.818 | 850.868 |
| doublewrite=off | 896.423 | 848.110 | 483.542 | 468.943 |
| doublewrite=off,checksums=none | 889.827 | 846.552 | 488.311 | 476.916 |
| doublewrite=off,checksums=none,P_S=off | 488.273 | 467.716 |
Hay varias cosas que comentar aquí, alguna de las cuales ni siquiera soy capaz de proporcionar una explicación:
- El doublewrite no reduce el rendimiento a la mitad, pero impacta de manera significativa en el rendimiento (entre un 15% y un 30%)
- Sin la escritura doble, la mayoría de la regresión de 5.7 desaparece (¿por qué?)
- El doublewrite es más significativo en 5.6 y 5.7 que en versiones previas de MySQL. Me atrevería a decir que la mayoría de otros cuellos de botella han sido eliminados (¿o quizá sea algo como las particiones del buffer pool estando activas por defecto?)
- Los checksums de innodb no producen absolutamente ninguna diferencia para este tipo de carga y hardware en particular.
- De nuevo, no puedo dar significado estadístico a una pérdida de rendimiento del performance schema. Sin embargo, he obtenido resultados muy variables en los tests, con resultados como un 10% de latencia extra en los valores centrales respecto aquellas con él deshabilitado, pero no estoy 100% seguro de esto.
En resument, con unos pocos cambios aquí y allí, podemos obtener resultados que tan sólo son el doble de lentos que MyISAM, en vez de 5 veces o 12 veces.
Importar en MyISAM, convertir a InnoDB
He visto a veces a algunas personas en los foros recomendar la importación de una tabla en formato MyISAM, y después convertirla a InnoDB. Veamos si podemos pillar o confirmar este mito con el siguiente código (load_data_06.py):
load_data = "LOAD DATA INFILE '/tmp/nodes.csv' INTO TABLE nodes"
alter_table = "ALTER TABLE nodes ENGINE=InnoDB"
cursor.execute(load_data)
cursor.execute(alter_table)
Esta es la comparación (menos es mejor):
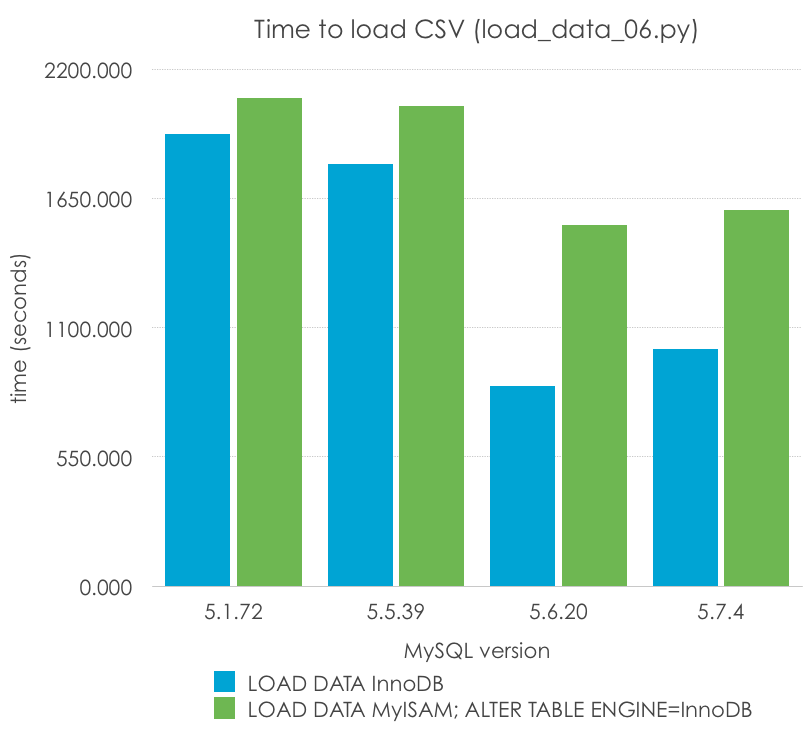
| MySQL Version | 5.1.72 | 5.5.39 | 5.6.20 | 5.7.4 |
| LOAD DATA InnoDB | 1923.751 | 1797.220 | 850.636 | 1008.349 |
| LOAD DATA MyISAM; ALTER TABLE ENGINE=InnoDB | 2075.445 | 2041.893 | 1537.775 | 1600.467 |
Puedo ver cómo esto podría ser casi cierto en 5.1, pero es claramente falso en todas las versiones soportadas de MySQL. Sin embargo, tengo que remarcar que es más rápido que importar la tabla dos veces, una para MyISAM y otra para InnoDB.
Dejaré como deberes para el lector comprobarlo para otros motores, como MEMORY o CSV [Pista: Quizá podemos importar a éste último motor de una manera diferente].
Carga de manera paralela
MyISAM escribe a las tablas usando un bloqueo a nivel de tabla (aunque en algunos casos es posible realizar inserts concurrentes), pero InnoDB sólo requiere un bloqueo a nivel de fila en muchos casos. ¿Podríamos acelerar el proceso realizando una importación en paralelo? Esto es lo que quise probar con mi último test. No confío en mis habilidades de programación (o más bien no tengo mucho tiempo) para realizar el movimiento de cursor de archivo y el particionamiento de manera eficiente, así que comenzaré con un .csv ya dividido en 8 trozos. No debería llevar mucho tiempo, pero las herramientas limitadas de la librería de threads por defecto, así como mi falta de tiempo me hicieron optar por este plan. Tan sólo debemos ser conscientes de que no comenzamos con el mismo escenario exacto en este caso. Este es el código (load_data_08.py):
NUM_THREADS = 4
def load_data(port, csv_file):
db = mysql.connector.connect(host="localhost", port=port, user="msandbox", passwd="msandbox", database="test")
cursor = db.cursor()
load_data_sql = "LOAD DATA INFILE '" + csv_file + "' INTO TABLE nodes"
cursor.execute(load_data_sql)
db.commit()
thread_list = []
for i in range(1, NUM_THREADS + 1):
t = threading.Thread(target=load_data, args=(port, '/tmp/nodes.csv' + `i`))
thread_list.append(t)
for thread in thread_list:
thread.start()
for thread in thread_list:
thread.join()
Y estos son los resultados, con diferentes parámetros (menos es mejor):
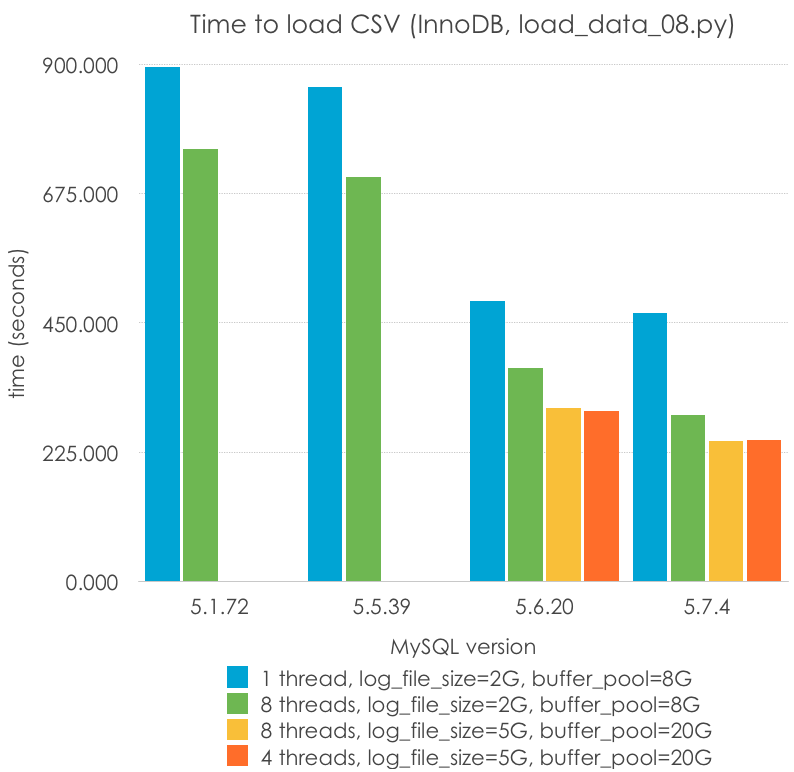
| MySQL Version | 5.1.72 | 5.5.39 | 5.6.20 | 5.7.4 |
| 1 thread, log_file_size=2G, buffer_pool=8G | 894.367 | 859.965 | 488.273 | 467.716 |
| 8 threads, log_file_size=2G, buffer_pool=8G | 752.233 | 704.444 | 370.598 | 290.343 |
| 8 threads, log_file_size=5G, buffer_pool=20G | 301.693 | 243.544 | ||
| 4 threads, log_file_size=5G, buffer_pool=20G | 295.884 | 245.569 |
En este método podemos ver que:
- Hay pocos cambios de rendimiento entre realizar la carga paralela con 4 u 8 threads. Esta es una máquina con 4 cores (8 HT)
- La paralelización ayuda, aunque no escala (4-8 hilos proporcionan alrededor de un 33% de velocidad)
- Éste es el caso en le que 5.6 y especialmente 5.7 destacan
- Un log de transacciones y un buffer pool mayor (de más de 4G, sólo disponible en 5.6+) siguen siendo útiles para reducir la carga
- La carga paralela con 5.7 es la manera más rápida en la que puedo cargar este archivo usando InnoDB: 243 segundos. Es 1.8x veces la manera más rápida en la que puedo cargar una tabla en MyISAM (5.1, monohilo): 134 seconds. ¡Esto son casi 200K filas/s!
Resumen y preguntas abiertas
- La manera más rápida en la que puedes importar una tabla en MySQL sin usar archivos binarios es usando la sintaxis
LOAD DATA. Usa la paralelización en InnoDB para mejorar los resultados, y recuerda ajustar parámetros básicos como el tamaño de archivo de transacciones y el buffer pool. Una programación y imporación hecha con el debido cuidado pueden convertir un problema de más de 2 horas en un proceso de apenas 2 minutos. Es posible deshabilitar temporalmente algunas características de seguridad para obtener rendimiento extra. - Parece haber una importante regresión en 5.7 para esta carga en particular de una importación monohlo tanto para MyISAM como para InnoDB, con unos resultados hasta un 15% peores en rendimiento que 5.6. Todavía no sé porqué.
- En el aspecto positivo, parece haber un aumento (de hasta el 20%) en relación con 5.6 en una carga paralela de escrituras.
- Es posible que haya un impacto en el rendimiento de Performance schema para este tipo de operación, pero soy incapaz de medirlo de manera fiable (es más cercando a 0 que mi error de medida). Esto es algo positivo.
Estaría agradecido si me pudierais indicar cualquier error en alguna de mis suposiciones.
Aquí podéis descargar los diferentes scripts de Python usados para probar la carga de datos en MySQL.
Recordad que esto no son benchmarks “formales”, y que ya no dispongo de acceso a la máquina donde los generé. Todavía tengo pendiente el analizar si existe el mismo problema en 5.7.5. Hay otras personas apuntando a regresiones bajo limitada concurrencia, como Mark Callaghan, quizá estén relacionados? Como de costumbre, podéis dejarme un comentario aquí o mandarme una respuesta mediante Twitter.
Pingback: Cambios en variables globales de configuración entre MySQL 5.6.20 y MySQL 5.7.4 “Milestone 14″ | Contrate un MySQL DBA